IntelのBoyd Phelpsが、10 nm SuperFinに組み込まれた同社の新しいTiger Lake CPUを披露します。
(Source:wccftech)
IntelのTiger Lake CPUは間もなくリリースされる予定です。Ice Lakeより性能が大幅に向上しています。Tiger Lake CPUは同社の10 nm SuperFinプロセスで製造されており、14 nmレベルのクロックとその他の主要なアーキテクチャの改善が可能です。結果、Tiger LakeのCPUは実際には最大5.0 GHzのクロックで動作します。これは、Intelの最も成熟した14 nmプロセスだけが成しえた性能です。
Intelの10 nm SuperFin TigerLake CPUは最大5.0 GHzで動作
Intelのオリジナルの10nmアーキテクチャであるSunny Coveには優れたIPCがありましたが、十分に高いクロックレートを維持できませんでした。これを修正するために、IntelはSuperFin(以前は10nm +と呼ばれていました)と呼ばれる新しいタイプのトランジスタを開発しました。+に惑わされないでください。以前のプラスとは異なり、この反復により、ノードが1回で縮小するのとほぼ同じレベルの改善が実現されました。Intelの10 nm SuperFinトランジスタの詳細については、こちらをご覧ください。
10 nm SuperFinアーキテクチャを備えたIntel Tiger Lake
Tiger Lakeは、帯域幅を2倍にし、ダブルリングアーキテクチャに移行するWillow Coveコアも利用しています。これは本質的に大幅に改良されたバージョンのSunny Coveであり、Intel SuperFinプロセスと組み合わせることで、Tiger Lakeを本当に手ごわい獣に変えます。Tiger Lakeには、同社の最初のXe iGPUも同梱されており、最大2.6 TFLOPのパフォーマンスを達成できます。
さっそくお話しましょう。クライアントエンジニアリンググループのバイスプレジデントであるIntelのBoyd Phelpsが、新しいTiger Lake CPUによるアーキテクチャの改善について説明しています。
ゲートプロセスを改善して駆動電流を増加させる新しい高性能トランジスタを追加し、より高い移動度を可能にすると同時に、ソースドレイン抵抗も低減しました。これをすべて、より低い容量で実現しました。高性能のために新しいデバイスを追加するだけではありません。ただし、Type-C、PCIE、イメージングなどの非高周波クリティカルIPSで使用されている既存の高VTデバイスも使用して、より効率的にしました。これらのデバイスを高速化し、リークを低減することができました。これにより、動作電圧を下げることができ、高性能IPSで利用できるように、より多くのパワーヘッドルームを利用できるようになりました。

しかし、優れた設計者なら誰でも知っているように、トランジスタよりも多くのことが必要です。ムーアの法則が機能サイズを縮小し続けるにつれて、金属スタックの相互接続性能はトランジスタ自体と同じくらい重要です。金属スタックも再設計するために、エンジニアリングの重点とリソースを投資しました。中間層の抵抗、可用性、および歩留まりを大幅に改善します。また、上部に2つの高性能レイヤーを追加し、mimcap機能を4倍以上に劇的に拡張して、高CPU負荷のワークロードに対して迅速かつ確実な電力供給応答を保証します。
新しいトランジスタテクノロジーと改善されたメタルスタックの組み合わせは、SuperFinテクノロジーと呼ばれるものであり、これらのエンジニアリング投資の結果は、私たちの期待を大幅に超えています。Tiger Lakeでの使用方法について説明します。
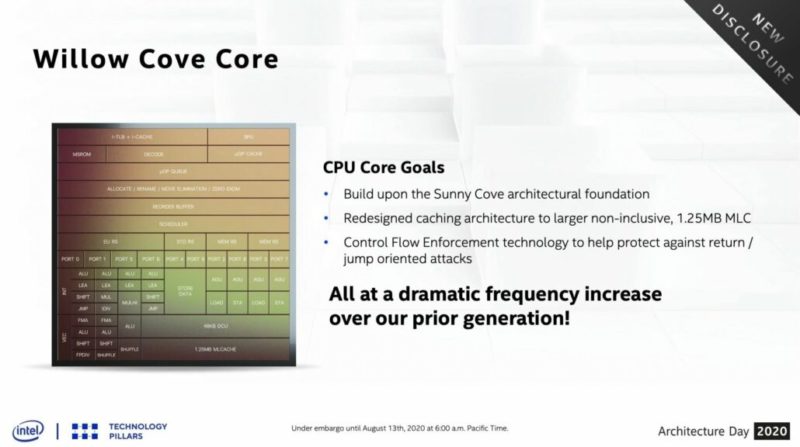
Willow Coveと呼ばれるTiger LakeのCPUの設計。私たちは3つの主要な目標によって推進されました。
1)このSunny Coveアーキテクチャの基盤の上に構築し、AI向けのより広くスマートで[区別できない]ハードウェアをすべて備えながら、大幅に高速化し、低電力で実行します。
2)キャッシングアーキテクチャを再設計して、ミッドレベルのキャッシュサイズを512キロバイトから1.25メガバイトに増やし、将来のパフォーマンスターゲットの増加と新たなワークロードに対応するため。
3)CETテクノロジーなどの機能で安全にするこれは、制御フロー指向の攻撃から保護するのに役立ちます。正直に言うと。追加のIPCに注力するのか、SuperFinプロセスの機能強化を利用するために基本回路を再設計するのかについて議論しました。
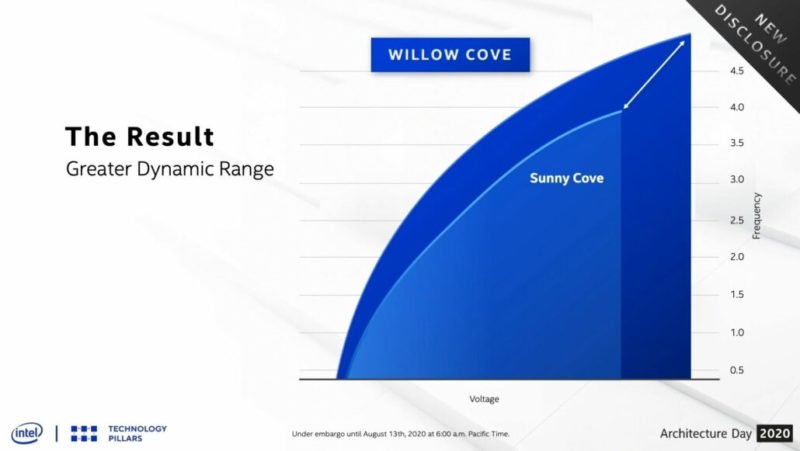
そして最終的に、私たちは正しいエンジニアリングの選択をしたと信じており、Willow Coveがサニーコーブに対して動作周波数を達成する電圧を劇的に下げるだけでなく、パフォーマンスについて世代を超えて向上させることができただけでなく、範囲を拡張します。Willow Coveはより高速で効率的であり、世代別のCPUゲインを実現し、TDPの制限されたパフォーマンスだけでなく、ボード全体で制約のないパフォーマンスも実現します。Willow Coveは、VFカーブの全範囲を最適化するように設計されました。このパフォーマンスのダイナミックレンジがどのように見えるかを説明しましょう。所定の電圧で、Willow Coveは周波数を大幅に増加させます。また、大幅に低い電圧で任意の固定周波数で動作できます。VRカーブ全体でのパフォーマンスです。V-MinからV-Maxまでのより大きなダイナミックレンジ。これはかなりの高揚です。今日は、実際のワークロードでこれがどのように見えるかをお見せしたいと思います。
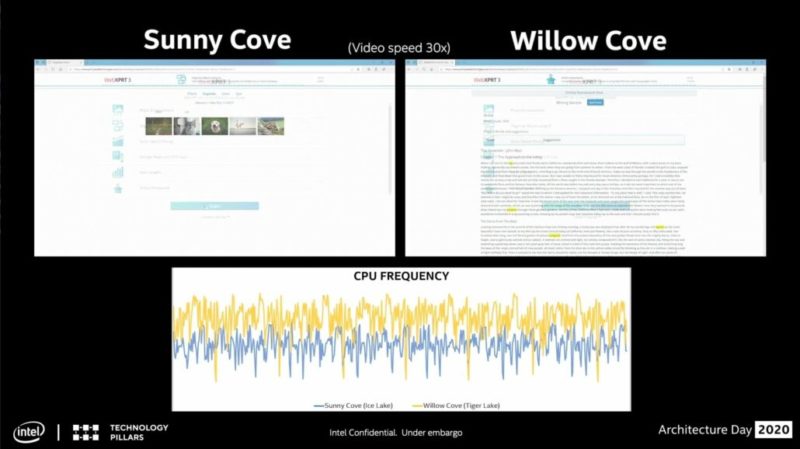
画面の上部に、Willow CoveとSunny Coveが並行して動作するWeb Expert 3を表示します。これは、HTML5とJavaScriptを使用したブラウザーベースのワークロードであり、周波数感度が高く、重要なWebブラウジングパフォーマンスのバースト性を表しています。今日の仕事量で。画面の下部には、ワークロードの実行中のWillow CoveおよびSunny Coveのリアルタイム周波数が表示されます。ワークロードが実行されると、複数のサブワークロードが連続して実行されるため、ワークロードが実行されるとCPUが急増し、ワークロードが完了すると次のCPUが起動するのを確認できます。Willow CoveがSunny Coveと同じかそれよりも低い電力で非常に高い周波数で実行されていることがはっきりとわかります。これによりパフォーマンスと応答性が向上します。
これは、CPUにSカーブのマイナス面がまったくないWillow Cove CPUの設計における私たちの目標でした。SuperFinプロセスの機能強化を利用して、グラフィックスへの電力の割り当て方法を変更しています。私たちはより多くのパワーヘッドルームを提供でき、そのヘッドルームとアーキテクチャの改善により、実行ユニットを64から96に増やし、同じパワーエンベロープ内でより高速に駆動することができました。また、AI機能を強化するためにハードウェアとデータタイプを追加しました。次のプレゼンテーションでは、David BlytheがXeの画期的なグラフィックスアーキテクチャについて説明します。

EUの数の増加に伴い、より多くの帯域幅が必要になり、その帯域幅を開放するために、Tiger Lakeを再設計してXEエンジンに供給する必要がありました。Tiger Lakeは、高帯域幅向けに設計され、さまざまなメモリテクノロジーをサポートします。前述のTiger Lakeで述べたように、リングと呼ばれる高速コヒーレントファブリックは、高性能コアとグラフィックスを接続するために使用されます。デュアルリングマイクロアーキテクチャを実装することにより、Ice Lakeのリング帯域幅を2倍にしました。SuperFinテクノロジーを活用して、電圧と周波数のスケーリング機能を改善しました。最後のレベルのキャッシュも、製品に応じて12メガバイトから24メガバイトの範囲で50%拡大し、同じ低ヒットレイテンシを維持しながらより多くのワーキングセットをキャプチャします。
 ここで、DRAMの効率を活用してメモリ帯域幅をより有効に利用するために、メモリを8 x 16バンドルに再編成し、より良いキューを持つ2つ目のメモリコントローラを追加して、スケジューリング効率を向上させました。Tiger Lakeアーキテクチャのメモリへの最大帯域幅は、最大86 GB / sまで拡張できます。Tiger Lakeの初期構成は、最大4267までのDDR4 3200 LP 4Xをサポートし、将来のバージョンのTiger Lakeが最大5400までのLP5テクノロジーをサポートすることを保証します。
ここで、DRAMの効率を活用してメモリ帯域幅をより有効に利用するために、メモリを8 x 16バンドルに再編成し、より良いキューを持つ2つ目のメモリコントローラを追加して、スケジューリング効率を向上させました。Tiger Lakeアーキテクチャのメモリへの最大帯域幅は、最大86 GB / sまで拡張できます。Tiger Lakeの初期構成は、最大4267までのDDR4 3200 LP 4Xをサポートし、将来のバージョンのTiger Lakeが最大5400までのLP5テクノロジーをサポートすることを保証します。

また、システムDIMMを保護するためにXDS AES暗号化復号化アルゴリズムをメモリトラフィックに適用するTotal Memory Encryption Engine(TME)を追加しました。Tiger Lakeでは、NNI命令を介したCPU AIアクセラレーションからGPU、GNA 2.0などの低電力アクセラレータまで、さまざまなワークロードに対応するさまざまなAI機能を提供しています。Tiger LakeのGNA 2.0のTDP電力は、1ミリワットあたり1 GigaOpで、最大38 GigaOpsの能力があります。これは、ノイズキャンセレーションなどのアルゴリズムや、音声文字変換の翻訳などのアプリケーション、およびもちろんコンテキストと会話の追跡を対象としています。
この低消費電力機能は、特に高品質の距離ベースのコラボレーションに重点を置いた今日の現代のモバイルCPUでますます重要になっています。Tiger Lakeは、表示およびイメージングの分野でも進歩を遂げています。ディスプレイについては、サポートできるディスプレイの数を増やすだけでなく、将来のディスプレイで出現するより高い解像度と品質にも対応したいと考えました。したがって、これはサービス品質を維持する必要があるため、はるかに高い帯域幅要件に変換されます。そのために、私たちはその要求を処理するためにTiger Lakeを再構築しました。メモリから64バイトのダイレクトデータパスをプラグインして表示し、これをディスプレイISOCポートと呼び、SOCファブリックのすべてのアービトレーションレイヤーをバイパスします。
現在、ディスプレイのISOCポートは、製品の実装に応じて、最大64ギガバイト/秒を簡単にサポートします。現在、IPUアーキテクチャを使用したイメージングにより、新しいテクノロジーで実現された新しいTiger Lakeカメラ機能がいくつかあります。イメージパイプラインが完全にハードウェアに実装され、低消費電力と高速応答性が実現しました。最大4K 90解像度のビデオと最大42メガピクセルの静止画像解像度をサポートできる最大6つのセンサーがあります。当社の最初の製品は、それぞれ4K 30メガピクセルと27メガピクセルをサポートします。

当社のIPU6アーキテクチャは、多数の新しいセンサーテクノロジーと品質向上もサポートしています。Tiger Lakeには、モバイルCPU用に実装されたIO機能の非常に豊富なセットがあり、プラットフォーム機能とフォームファクターの新しい配列を可能にします。Tiger Lakeは、完全に仕様に準拠した統合Thunderbolt 4とUSB 4を導入しています。タイプCシステムを介した統合ディスプレイは、Thunderboltを介した以前のDPトンネリングに基づいて構築されていますが、重要なのは、ディスクリートカードDisplayPort出力用のDPNポートを追加して、SKU構成に応じて統合Type-Cポートに多重化することです。PCIeでは、応答性を高めるために、PCHを経由せずにCPUに直接SSDを接続できるようにするPCI Gen4レーンを追加しました。

これは、PCH経由での接続に比べて100ナノ秒の遅延が少ない高速ストレージデバイスに最適であるだけでなく、他の興味深い構成も可能です。たとえば、グラフィックカードを接続できるとします。レーンの数は、コア数の構成と電力レベルに依存します。次に、電力とパフォーマンスを改善して攻撃的な目標を達成するために、2つの別々の電力管理作業に取り組みました。1)Tiger Lakeは、周波数と電圧を実行中のワークロードに必要な帯域幅に動的に一致させるように設計されています。

当社の自律dbfs機能は、SOCファブリックとメモリサブシステムの両方のワークロード帯域幅に基づいて、電力と周波数の低遅延スケーリングを実現し、最も電力効率の高いポイントで実行します。dbfs機能に加えて、設計のいくつかの領域を対象として、追加されたすべての機能とパフォーマンスを備えた場合でも、消費電力を削減しています。改良されたHVTトランジスタは、Type-C、PCIe、およびDVR IOサブシステムの電力を向上させるために不可欠です。
完全に統合された電圧レギュレータの効率を改善しながら、可能な限りIce Lakeの固定レール電圧を下げました。また、ディープスリープCステートの持続的なレールで動作するために必要なロジックの量を減らします。最終的に、これらの作業ストリームの両方により電力効率が向上しました。これは、同じ電力エンベロープでより高いパフォーマンスを発揮し、エネルギー消費を削減することを意味します。

全体的にIce Lakeと比較して、Tiger Lake SOCアーキテクチャが説明した優れたプロセステクノロジーの改善を活用することで、Willow Coveの世代を超えたCPUパフォーマンスの向上だけでなく、幅広いSOC IPに大きな進歩をもたらし、グラフィックスの電力効率が大幅に向上します。 XEグラフィックスIP、新しいクライアントワークロード向けのスケーラブルAI、メモリおよびファブリック効率の向上により、高帯域幅と豊富なIO機能などをサポートします。私たちがTiger Lakeの旅に興奮している理由をご理解いただければ幸いです。Intelチームは、SuperFinテクノロジーの基盤に基づいてSOCを再設計し、CPU、GPU、AI全体でより優れたパフォーマンスを提供します。電力効率の向上により、既存のすべてのIPを更新および更新できるだけでなく、しかし、さまざまな機能を統合して、さまざまなユーザーエクスペリエンスを向上させることができました。– Boyd Phelps, Vice President Client Enigneering Group, Intel, Architecture Day 2020.