
(Source:wccftech)
AMDのRDNA 2とNVIDIAのAmpere GPUアーキテクチャのメモリレイテンシ性能はChips and Cheeseによってテストされました。最新のGPUアーキテクチャのGPUメモリレイテンシパフォーマンスをテストすることを決定し、いくつかの興味深い結果を見つけました。
AMDのRDNA2 GPUは、NVIDIAのAmpere GPUアーキテクチャと比較して優れたメモリレイテンシパフォーマンスを備える
CPU側では、キャッシュとレイテンシのパフォーマンスを測定することが重要な指針になり、同じダイに搭載されたマルチチップレットダイと複数のIOチップ、そして最近ではオフダイ(AMD Zenチップレット)の使用が増え続けています。GPUは、コンピューティングとメモリのパフォーマンスの間のギャップを埋めるいくつかのキャッシュ階層で構成され、ソースは、NVIDIA AmpereやAMD RDNA2などの現世代のGPUでキャッシュとメモリのレイテンシパフォーマンスを測定するためにOpenCLベースのポインター追跡ベンチマークを使用しました。
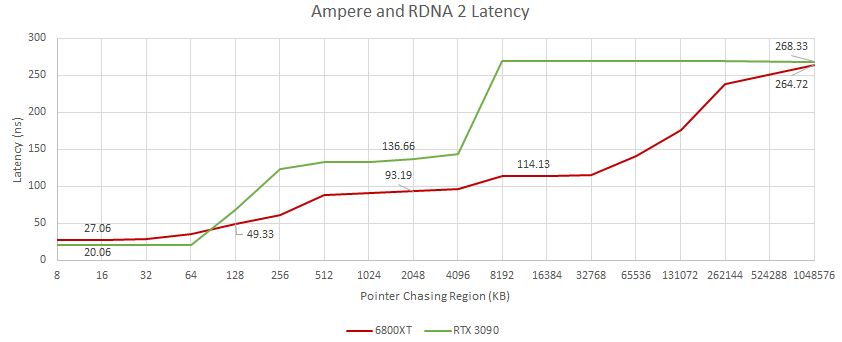
ベンチマークでは、AMD Radeon RX6800XT(RDNA 2 GPU)とNVIDIA GeForce RTX 3090(Ampere GPU)が比較されています。キャッシュとメモリのベンチマークは、AMDのRDNA2アーキテクチャがNVIDIAのAmpere GPUよりもはるかに優れており、メモリに向かう途中でさらに2レベルのキャッシュをチェックする必要があるにもかかわらず、レイテンシが低いことを示しています。Infinityキャッシュを使用すると、L2ヒットに20nsしか追加されず、NVIDIAのAmpereよりも高速です。NVIDIA AmpereベースのGA102GPUは単純にはるかに大きなGPUであり、2つのキャッシュレベルしかない従来のGPUメモリサブシステムを使用しますが、多くのサイクルを必要とし、L1 L2へ100nsを超える遅延が発生するためです。一方、RDNA2のレイテンシはわずか66nsです。AMD Navi 21 GPUははるかに小さく、4MBのL2キャッシュを備えていますが、NVIDIA GA102GPUはチップ全体で6MBのL2キャッシュを備えています。HPC用のNVIDIA A100 Ampere GPUは、大容量の40 MBL2キャッシュを備えています。

Following is a note on the performance from Chips and Cheese
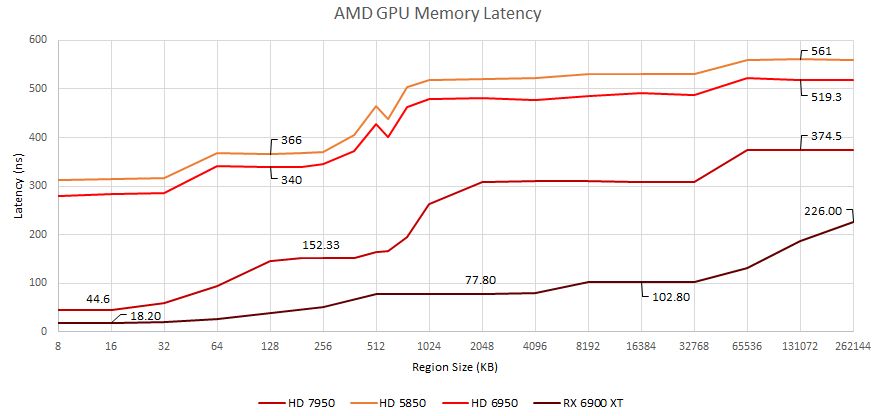
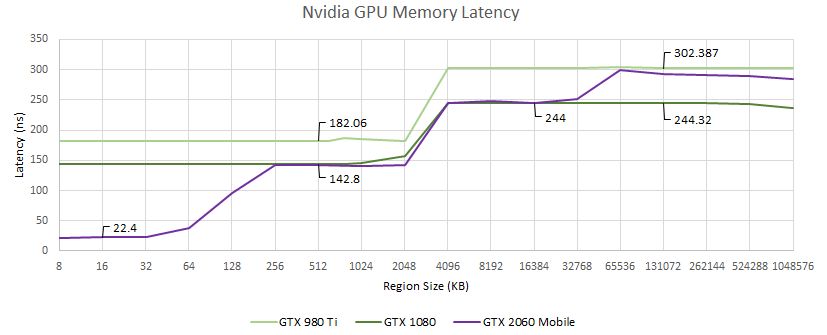
古いPascalおよびMaxwellチップと比較して、Ampereアーキテクチャにより、はるかに大きなGPUでのレイテンシ速度が大幅に向上しました。一方、AMDは、古いGCNおよびVLIWアーキテクチャベースのチップと比較して、いくつかの目覚ましい進歩を示しています。これらの数値は、チップレットベースのGPUの新ラウンドが今後数年間でゲームセグメントに登場すると、比較するにあたり興味深いものになるでしょう。

















