
(Source:wccftech)
NVIDIAは、GeForce RTX 30シリーズグラフィックスカードが使用するAmpere GPUに関して、報道機関に詳細情報が提供されました。今後数週間内にゲーム市場に登場するGA102とGA104の両方のゲームAmpere GPUの詳細なNDAセッションの一部です。
NVIDIA GeForce RTX 30シリーズグラフィックスカードの仕様、パフォーマンス、GA102 / GA104 GPUの詳細
詳細セッションには、NVIDIA GeForce RTX 30シリーズに関する情報が含まれます。そのうちのいくつかは、9月1日の公式発表ですでに確認されており、一部にはAmpereゲーミングGPUの詳細を示す新しい情報が含まれています。NVIDIAは、Reddit Q&Aセッション中に少量の情報を詳しく説明しました。そこでは、Ampere GPUの新しいSM設計について話しました。NVIDIAの新しいGeforce RTX 30シリーズラインナップを強化するGPUを見てみましょう。次の画像はHardwareluxx.deの厚意によるものです。
NVIDIA GA102 GPU-GeForce RTX 3090およびRTX 3080のフラッグシップAmpere ゲームGPU
NVIDIA GA102 GPUは、ダイサイズが628mm2で、合計で28億個のトランジスタを搭載したフラグシップゲーミングチップです。NVIDIAによると、GA102 GPUは、グラフィックス処理クラスターである6つのGPCと6つのTPC(テクスチャー処理クラスター)で構成されています。RTX 3090のGA102 GPUは41 TPCまたは82 SMを使用し、GeForce RTX 3080は34 TPCまたは68 SMを使用します。Ampere GPUの各SMは、128のCUDAコアと、再設計された構造を備えています。RTX 3090のGA102 GPUは合計10,496コアを備え、RTX 3080のGPUは8704コアを備えています。GPU密度に関して、GA102 GPUは、Turing TU102 GPUの約2倍の密度で、1平方ミリメートルあたり4456万トランジスタであるのに対し、Turingでは2467万トランジスタあたり1平方ミリメートルであり、これはすべてSamsung 8nmプロセスノード上にあります。

各SMは4つのTensorコアと1つのRTコアで構成されます。GA102 GPUは共有L2キャッシュを備えています。GeForce RTX 3090の場合は6 MB、RTX 3080の場合は5 MBです。共有されている特定のGPUブロック図は、320ビットバスを提供するGeForce RTX 3080の合計10個の32ビットメモリコントローラーを示しています。GeForce RTX 3090は、384ビットバスインターフェイス用に合計12個の32ビットメモリコントローラーを備えています。
NVIDIA GA104 GPU-GeForce RTX 3070向けの効率とゲームに最適化されたGPU
NVIDIA GeForce RTX 3070グラフィックスカードの中心には、GA104 GPUがあります。GA104は、ゲームセグメントで採用される多くのAmpere GPUの1つです。GA104 GPUは、スタックで2番目に高速なAmpere チップです。GPUはSamsungの8nm(N8)プロセスノードに基づいています。GPUのサイズは395.2mm2で、TU102 GPUに搭載されているトランジスタのほぼ93%である174億個のトランジスタを備えています。同時に、GA104 GPUは、非常に密度の高いTU102 GPUのサイズのほぼ半分です。
GeForce RTX 3070の場合、NVIDIAはフラグシップで合計46のSMユニットを有効にし、合計5888のCUDAコアを実現しました。CUDAコアに加えて、NVIDIAのGeForce RTX 3070には、次世代のRT(レイトレーシング)コア、Tensorコア、新しいSMまたはストリーミングマルチプロセッサユニットも搭載されています。GPUは、合計184個のTensorコアと46個のRTコアを備えています。GA104 GPUには、将来のグラフィックスカードで起動する可能性のあるFull fat 6144コア構成が付属している可能性が非常に高くなります。GA104 GPUは4 MB L2共有キャッシュを特徴とし、256ビット幅のバスインターフェイス用に合計8つの32ビットメモリコントローラーを備えています。
NVIDIA GeForce RTX 30 Series ‘Ampere’ Graphics Card Specifications
| Graphics Card Name | NVIDIA GeForce RTX 3070 | NVIDIA GeForce RTX 3080 | NVIDIA GeForce RTX 3090 |
|---|---|---|---|
| GPU Name | Ampere GA104-300 | Ampere GA102-200 | Ampere GA102-300 |
| Process Node | Samsung 8nm | Samsung 8nm | Samsung 8nm |
| Die Size | TBD | TBD | TBD |
| Transistors | TBD | 28 Billion | 28 Billion |
| CUDA Cores | 5888 | 8704 | 10496 |
| TMUs / ROPs | TBD | TBD | TBD |
| Tensor / RT Cores | TBD | TBD | TBD |
| Base Clock | 1500 MHz | 1440 MHz | 1400 MHz |
| Boost Clock | 1730 MHz | 1710 MHz | 1700 MHz |
| FP32 Compute | 20 TFLOPs | 30 TFLOPs | 36 TFLOPs |
| RT TFLOPs | 40 TFLOPs | 58 TFLOPs | 69 TFLOPs |
| Tensor-TOPs | 163 TOPs | 238 TOPs | 285 TOPs |
| Memory Capacity | 8/16 GB GDDR6 | 10/20 GB GDDR6X | 24 GB GDDR6X |
| Memory Bus | 256-bit | 320-bit | 384-bit |
| Memory Speed | 16 Gbps | 19 Gbps | 19.5 Gbps |
| Bandwidth | 512 Gbps | 760 Gbps | 936 Gbps |
| TDP | 220W | 320W | 350W |
| Price (MSRP / FE) | $499 US | $699 US | $1499 US |
| Launch (Availability) | 2020-10-01 00:00:00 | 17th September | 24th September |
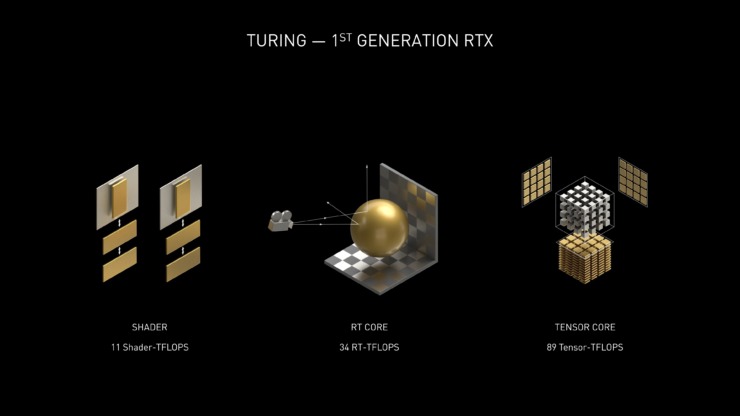
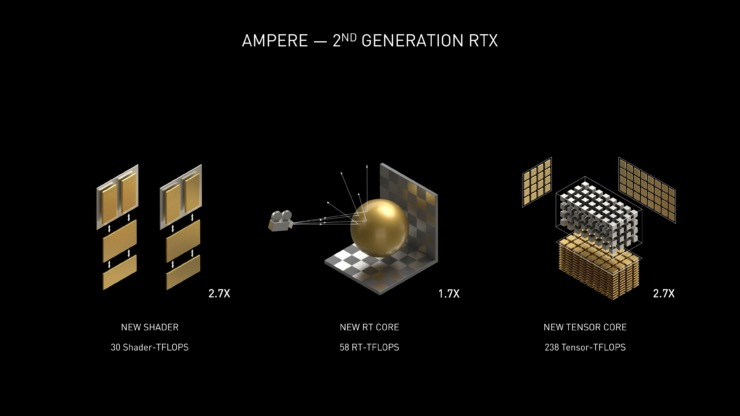
NVIDIA Ampere SM(ストリーミングマルチプロセッサデザイン)-2倍のFP32スループット
Ampere GPUを備えたNVIDIA GeForce RTX 30シリーズカードには、最近Tony Tamasiが説明した新しいSMデザインも付属しています。以下は、SMAmpere キテクチャの新機能の詳細です。
 Ampere 30シリーズSMの主要な設計目標の1つは、Turing SMと比較して、FP32オペレーションのスループットを2倍にすることでした。この目標を達成するために、Ampere SMには、FP32およびINT32操作用の新しいデータパス設計が含まれています。各パーティションの1つのデータパスは、クロックごとに16のFP32操作を実行できる16のFP32 CUDAコアで構成されています。別のデータパスは、16個のFP32 CUDAコアと16個のINT32コアの両方で構成されています。この新しい設計の結果、各Ampere SMパーティションは、クロックごとに32のFP32オペレーション、またはクロックごとに16のFP32および16のINT32オペレーションを実行できます。4つのSMパーティションをすべて組み合わせると、1クロックあたり128のFP32演算を実行できます。これは、Turing SMのFP32レートの2倍、または1クロックあたり64のFP32および64 INT32演算です。
Ampere 30シリーズSMの主要な設計目標の1つは、Turing SMと比較して、FP32オペレーションのスループットを2倍にすることでした。この目標を達成するために、Ampere SMには、FP32およびINT32操作用の新しいデータパス設計が含まれています。各パーティションの1つのデータパスは、クロックごとに16のFP32操作を実行できる16のFP32 CUDAコアで構成されています。別のデータパスは、16個のFP32 CUDAコアと16個のINT32コアの両方で構成されています。この新しい設計の結果、各Ampere SMパーティションは、クロックごとに32のFP32オペレーション、またはクロックごとに16のFP32および16のINT32オペレーションを実行できます。4つのSMパーティションをすべて組み合わせると、1クロックあたり128のFP32演算を実行できます。これは、Turing SMのFP32レートの2倍、または1クロックあたり64のFP32および64 INT32演算です。
FP32の処理速度を2倍にすると、多くの一般的なグラフィックスおよび計算操作とアルゴリズムのパフォーマンスが向上します。最新のシェーダーワークロードには、通常、FFMA、浮動小数点加算(FADD)、浮動小数点乗算(FMUL)などのFP32算術命令と、データのアドレッシングおよびフェッチのための整数加算、浮動小数点比較などのより単純な命令が組み合わされています。または結果を処理する場合の最小/最大など。パフォーマンスの向上は、命令の組み合わせによって、シェーダーおよびアプリケーションレベルで異なります。レイトレーシングノイズ除去シェーダーは、FP32スループットを2倍にすることで大きなメリットが得られる良い例です。演算スループットを2倍にするには、それをサポートするデータパスを2倍にする必要がありました。そのため、Ampere SMは、SMの共有メモリとL1キャッシュのパフォーマンスも2倍にしました。(Ampere SMあたり128バイト/クロック対Turingの64バイト/クロック)。GeForce RTX 3080の合計L1帯域幅は219 GB /秒ですが、GeForce RTX 2080 Superの場合は116 GB /秒です。以前のNVIDIA GPUと同様に、Ampereはグラフィックス処理クラスター(GPC)、テクスチャー処理クラスター(TPC)、ストリーミングマルチプロセッサー(SM)、ラスターオペレーター(ROPS)、およびメモリコントローラーで構成されています。GPCは主要な高レベルのハードウェアブロックであり、すべての主要なグラフィックス処理ユニットがGPC内に常駐しています。各GPCには専用のラスターエンジンが含まれ、NVIDIA Ampere Architecture GA10x GPUの新機能である2つのROPパーティション(各パーティションに8つのROPユニットを含む)も含まれるようになりました。NVIDIA Ampereアーキテクチャの詳細については、NVIDIAのAmpereアーキテクチャホワイトペーパーをご覧ください。このホワイトペーパーは、近日中に公開される予定です。
Ampere SMユニットを詳しく見ると、各ブロックは128個のFP32ユニットで構成されています。ただし、2つのFP32データパスの1つでもINT32演算を同時に実行できます。Tensorコアは4つのユニットで構成され、SMごとに4つのテクスチャユニットと1つのRTコアがあります。
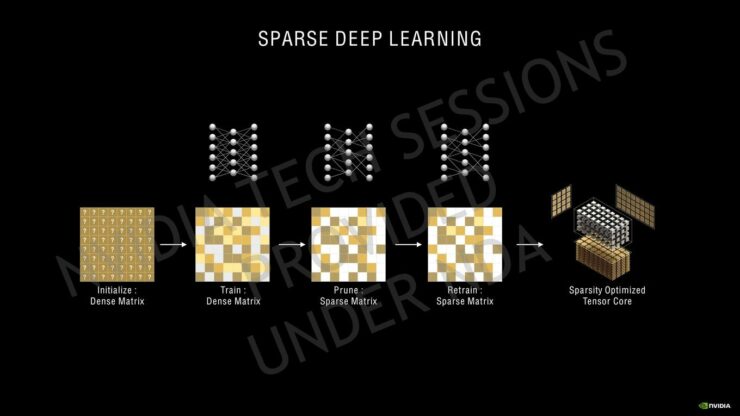
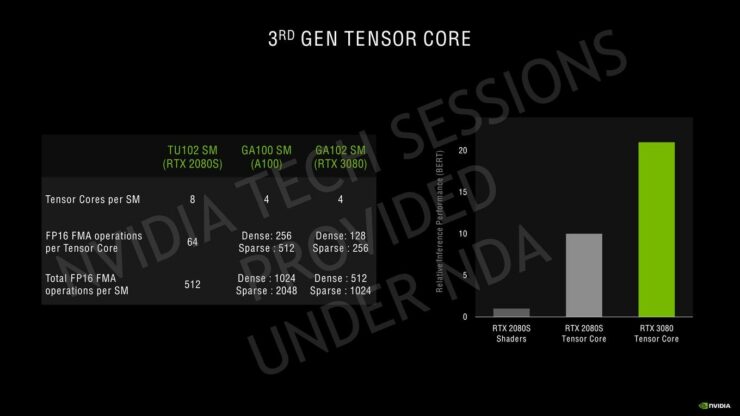
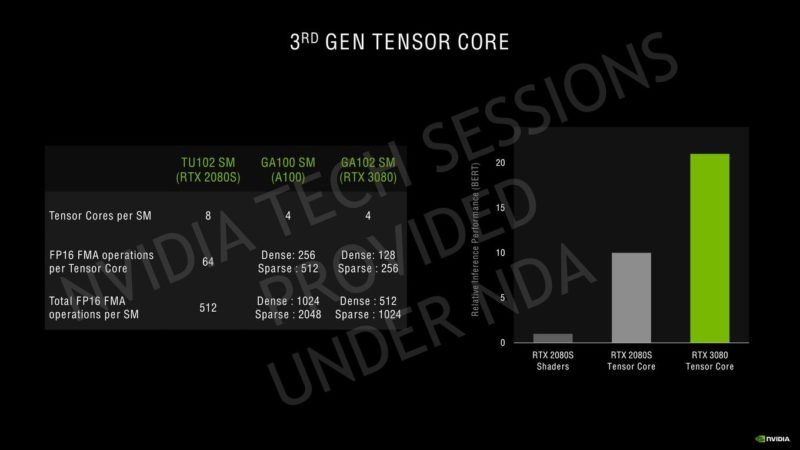
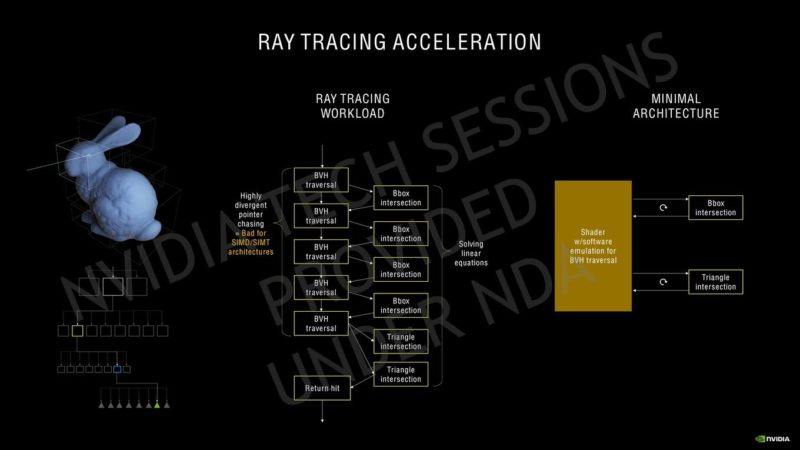
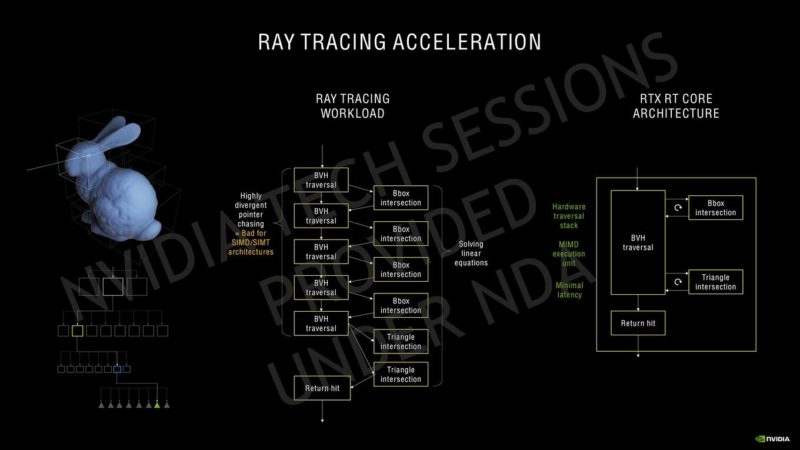
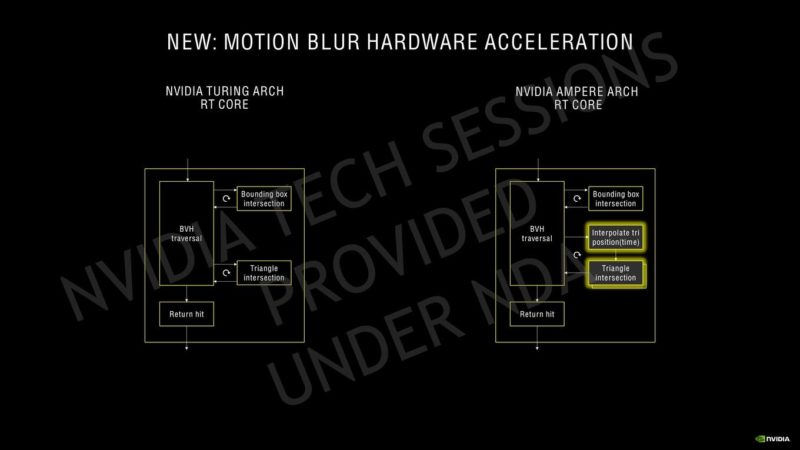

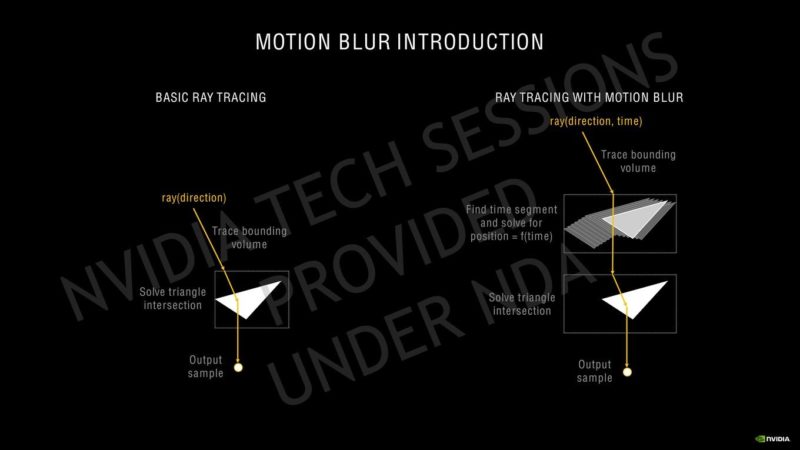
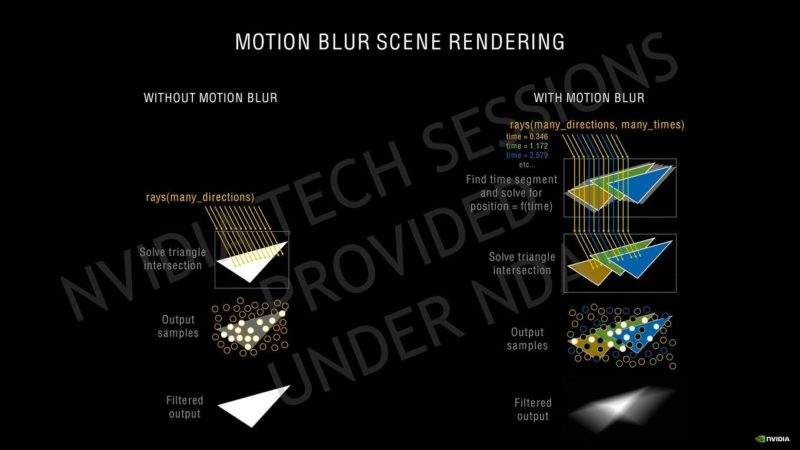







NVIDIAはその第3世代Tensorコアについて、GPUのAmpere HPCラインで使用されているのと同じスパース性アーキテクチャを使用しています。Ampereは、SMあたり4つのTensorコアを備えていますが、SMあたりのTuringの8 Tensorコアと比較すると、新しい第3世代の設計に基づいているだけでなく、より大きなSMアレイで数が増えています。Ampere GPUは、INT16コア全体を利用してTensorコアごとに128のFP16 FMA演算を実行でき、スパース性で最大256を実行できます。SMごとの合計FP16 FMA演算は、スパース性によって512および1024に増加します。これは、更新されたTensor設計での推論パフォーマンスに関して、Turing GPUの2倍の増加です。同じことがレイトレーシングコアにも当てはまり、2回目の反復では、Turingアーキテクチャと比較して2倍の数のレイトレーシングを提供します。SMの数が増えると、RTコアの数も増えます。これは、Ampereでのレイトレーシングアクセラレーションの全体的なパフォーマンスにも影響します。
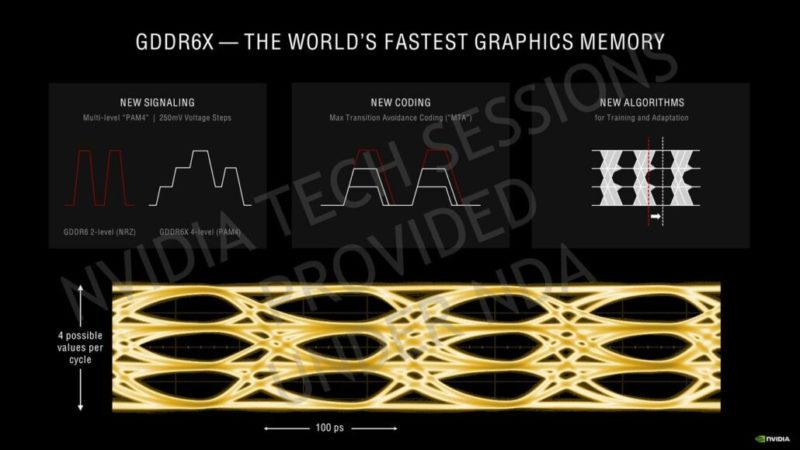
GDDR6X-NVIDIAのGeForce RTX 30シリーズグラフィックスカード専用に設計された、グラフィックスメモリの次の進化
Micron GDDR6Xメモリは、テーブルに多くの新しいものをもたらします。より高速で、I / Oデータレートが2倍になり、メモリダイにPAM4マルチレベルシグナリングを実装した最初の製品です。Geforce RTX 3090クラスの製品により、MicronのGDDR6Xメモリは最大1 TB / sの帯域幅を実現し、8Kなどの高解像度で次世代のゲーム体験を強化するために使用されます。
新しいGDDR6X SGRAM
- トランザクションあたりの消費電力を抑えながらSGRAMのデータレートを2倍にしながら、グラフィックカードアプリケーションの1秒あたり1テラバイト(TB / s)のシステムメモリ帯域幅境界を破ることができます。
- プロセッサとDRAM間でPAM4エンコードされたシグナリングを使用する最初のディスクリートグラフィックスメモリデバイスで、4つの電圧レベルを使用して、インターフェイスクロックごとに2ビットのデータをエンコードおよび転送します。
- 高速安定設計・量産対応が可能です。
前述のように、GDDR6Xはまったく新しいPAM4マルチレベルシグナリングテクニックを特徴としており、データの転送を大幅に高速化し、I / Oレートを2倍にし、各メモリダイの機能を64 GB / sから84 GB / sに押し上げます。Micron GDDR6Xメモリダイも、PAM4シグナリングを備えながら大量生産できる唯一のグラフィックスDRAMです。

興味深いのは、MicronがそのGDDR6Xメモリが最大21 Gbpsの速度に達する可能性があることを引用しているのに対し、GeForce RTX 3090では19.5 Gbpsでしか動作していないことです。Micronはまた、2021年に21 GB / sを超える速度を提供することを計画していることを確認していますが、今後更新し、カードがそれらを利用するかどうか確認する必要があります。速度が速いだけでなく、MicronのGDDR6Xは、前の世代のGDDR6メモリと比較して、転送ビットあたり15%低い電力を消費しながら、より高い帯域幅を提供します。
Micron GDDR6X Memory
| Feature | GDDR5 | GDDR5X | GDDR6 | GDDR6X |
|---|---|---|---|---|
| Density | From 512Mb to 8Gb | 8Gb | 8Gb, 16Gb | 8Gb, 16Gb |
| VDD and VDDQ | Either 1.5V or 1.35V | 1.35V | Either 1.35V or 1.25V | Either 1.35V or 1.25V |
| VPP | N/A | 1.8V | 1.8V | 1.8V |
| Data rates | Up to 8 Gb/s | Up to 12Gb/s | Up to 16 Gb/s | 19 Gb/s, 21 Gb/s, >21 Gb/s |
| Channel count | 1 | 1 | 2 | 2 |
| Access granularity | 32 bytes | 64 bytes 2x 32 bytes in pseudo 32B mode | 2 ch x 32 bytes | 2 ch x 32 bytes |
| Burst length | 8 | 8/16 | 16 | 8 in PAM4 mode 16 in RDQS mode |
| Signaling | POD15/POD135 | POD135 | POD135/POD125 | PAM4 POD135/POD125 |
| Package | BGA-170 | BGA-190 | BGA-180 | BGA-180 |
| 14mm x 12mm 0.8mm ball pitch | 14mm x 12mm 0.65mm ball pitch | 14mm x 12mm 0.75mm ball pitch | 14mm x 12mm 0.75mm ball pitch | |
| I/O width | x32/x16 | x32/x16 | 2 ch x16/x8 | 2 ch x16/x8 |
| Signal count | 61 | 61 | 70 or 74 | 70 or 74 |
| - 40 DQ, DBI, EDC | - 40 DQ, DBI, EDC | - 40 DQ, DBI, EDC | - 40 DQ, DBI, EDC | |
| - 15 CA | - 15 CA | - 24 CA | - 24 CA | |
| - 6 CK, WCK | - 6 CK, WCK | - 6 or 10 CK, WCK | - 6 or 10 CK, WCK | |
| PLL, DCC | PLL | PLL | PLL, DCC | DCC |
| CRC | CRC-8 | CRC-8 | 2x CRC-8 | 2x CRC-8 |
| VREFD | External or internal per 2 bytes | Internal per byte | Internal per pin | Internal per pin 3 sub-receivers per pin |
| Equalization | N/A | RX/TX | RX/TX | RX/TX |
| VREFC | External | External or Internal | External or Internal | External or Internal |
| Self refresh (SRF) | Yes Temp. Controlled SRF | Yes Temp. Controlled SRF Hibernate SRF | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off | Yes Temp. Controlled SRF Hibernate SRF VDDQ-off |
| Scan | SEN | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) | IEEE 1149.1 (JTAG) |
NVIDIA GeForce RTX 30シリーズ冷却設計とサーマル
NVIDIAは、GeForce RTX 30シリーズグラフィックスカード向けに、これまでで最高かつ最も強力なFounders Edition冷却設計の1つを開発しました。NVIDIAは、より高いパフォーマンスには新しい形式の冷却ソリューションが必要であることを説明しました。そのため、いくつかの新しいおよび既存のテクノロジーを利用することで、GPUを静かに保ちながら静かに動作させる、次世代カード用の独自の冷却ソリューションを用意しました。
Founders Editionの冷却は、両面アキシャルテクノロジーベースのファンを備えたハイブリッドベーパーチャンバーを利用したフルアルミニウム合金ヒートシンクを利用しています。クーラーヒートシンクはナノカーボンコーティングでコーティングされており、温度を管理する上で非常に優れています。
 フィンとヒートパイプのデザインだけでなく、すべてがうまくいくという意味でデザインは興味深いものです。これは、はるかに大きなヒートシンク領域を利用する初代ファウンダーズエディションGeForce GTX 780以来、この種の最初のデザインです。
フィンとヒートパイプのデザインだけでなく、すべてがうまくいくという意味でデザインは興味深いものです。これは、はるかに大きなヒートシンク領域を利用する初代ファウンダーズエディションGeForce GTX 780以来、この種の最初のデザインです。
また、前面と下部に1つずつユニークなファンの配置が用意されています。言及されているように、排気口から熱をはるかに効果的に押し出すと言われているこのプッシュ&プルファン構成。カード自体の裏側からケース内に吹き出される空気がいくつかありますが、最新のCPUエアまたはリキッドクーラーはケース内から空気を排出するのに非常に優れているため、これは大きな問題にはなりません。




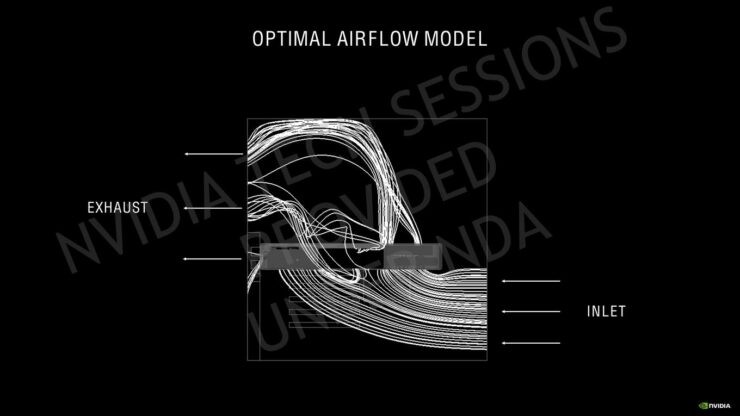
音響的には、新しいFounders Edition設計は従来のデュアルアキシャルクーラーよりも静かですが、前世代のソリューションのほぼ2倍の冷却性能を提供します。前述のNVLinkと電源設計の変更はここで役立ち、これまでに見られた最大のフィンスタックを通る空気の流れのためのより多くのスペースを作成し、より大きなブラケットの通気孔は、個々の形状のシュラウドフィンと連携して空気の流れを改善します。実際、どこを見ても、Founders Editionカードのすべての側面は、空気の流れを最大化し、温度を最小化し、ノイズを最小限に抑えて最高レベルのパフォーマンスを実現するように設計されています。
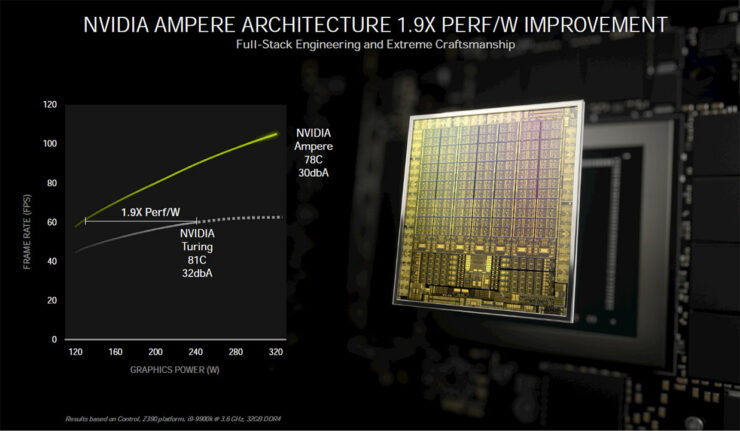
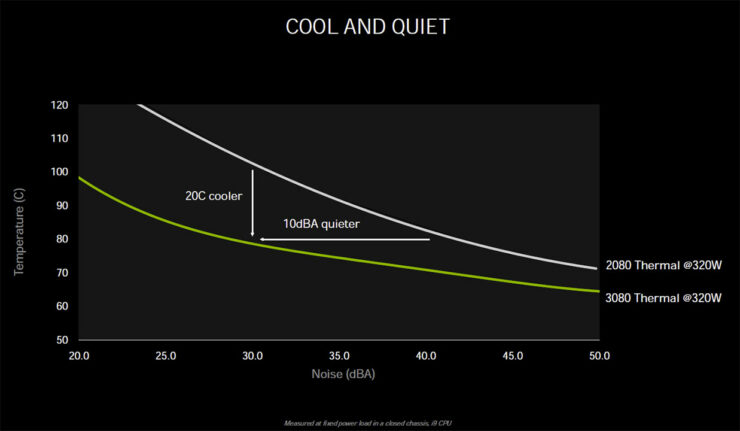

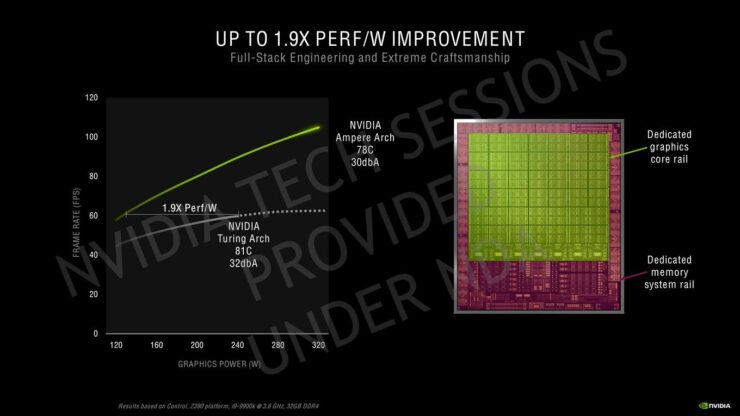
より涼しいノイズとパフォーマンスの面で、GeForce RTX 3080は、30dBAのノイズ出力で320WのピークTBPに達すると、78Cのピーク温度で動作します。比較のために、Turing Founders Editionのクーラーは、TBPが240W(RTX 2080 SUPER)に達したときに、ノイズ出力32dBAで81Cでピークに達します。NVIDIA自身のテストでは、GeForce RTX 3080の平均は約1920 MHzで、GPU消費電力は310 W、ピーク温度は76 Cであることを明らかにしています。
これはまた、RTX 3080が100 FPS以上を提供しながら、前世代のTuring世代の60 FPSに比べて涼しく静かなため、NVIDIAが1.9倍の効率の数値を得るところでもあります。
NVIDIA GeForce RTX 3090、RTX 3080、RTX 3070 Founders Editionギャラリー









NVIDIA GeForce RTX 3090およびRTX 3080グラフィックスカードPCBおよび電源-オーバークロックするように設計されています!
Founders Edition GeForce RTX 3090グラフィックスカードの最大の変更点の1つは、PCBデザインです。GeForce RTX 3090およびGeForce RTX 3080には、これまで消費者スペースで見られたものとは異なるユニークでコンパクトなPCBパッケージが付属しています。しかし、コンパクトであることは、カードがパンチを詰め込まないことを意味しません。NVIDIAが設計したこれらのコンパクトなPCBには、いくつかの魅力的な馬力があります。

PCBは20を超えるパワーチョークを備えており、フラッグシップの非参照RTX 20シリーズカードよりも優れた設計になっています。GPUは18フェーズで駆動され、メモリは2フェーズから電力を受け取ります。NVIDIAは、このPCBを、ほとんどのユーザーがより高速なパフォーマンスを得るために活用できる前例のないGPUオーバークロックヘッドルームを備えたオーバークロックの驚異として売り込んでいます。しかし、以前に指摘したように、Founders Edition PCBはリファレンスデザインではなく、標準の長方形PCBが付属します。ウォーターブロックメーカーもこれを確認しました。

さらに、GeForce RTX 30シリーズのファウンダーズエディションカードには、12ピンMicro-Fit 3.0電源コネクタが搭載されます。これらのコネクタは、2x 8ピンから1x 12ピンコネクタがバンドルされた状態で出荷されるため、電源装置のアップグレードを必要とせず、互換性の問題なしに最新のグラフィックスカードを実行できます。PCB上の12ピンコネクタの配置も注目に値します。それは垂直位置に配置され、PCBデザインから判断すると、NVIDIAが標準のデュアル8ピンデザインではなく、シングル12ピンプラグに移行した理由がわかります。PCBには、物事を行う余地が限られているため、より小型でコンパクトな電源入力を使用する必要がありました。
NVIDIA GeForce RTX 30シリーズのパフォーマンス、発売、価格
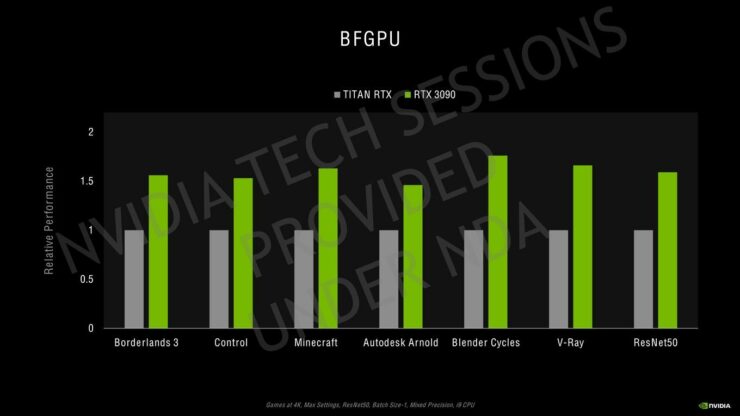
NVIDIAは、GeForce RTX 3090、GeForce RTX 3080、およびGeForce RTX 3070グラフィックスカードについて、以下に示す追加のパフォーマンス数値も共有しています。
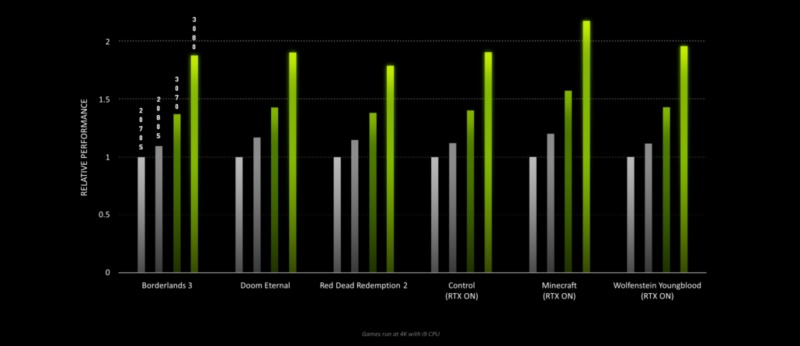
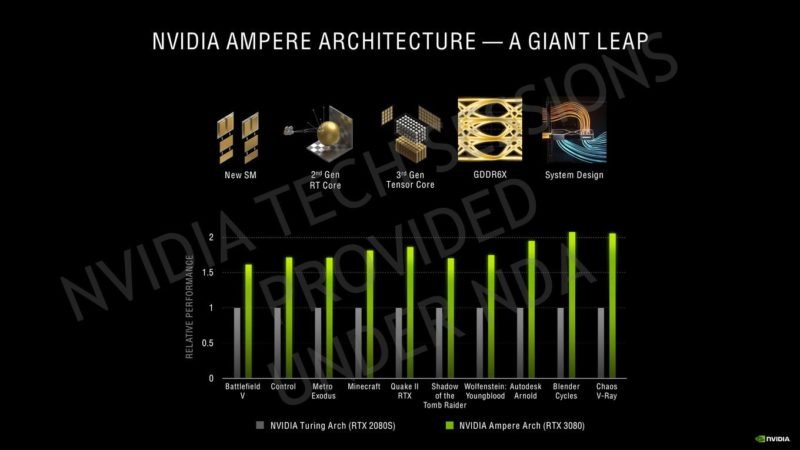
NVIDIAが現在共有しているパフォーマンスの数値はありませんが、これまでに示したものから、GeForce RTX 3070はRTX 2080 Tiよりも高速で、RTX 3080はRTX 2080 Tiよりもかなり優れており、RTX 3090はRTX 2080 Tiよりも約50%高速で、フルラインナップスタックには非常に印象的です。
他のニュースでは、NVIDIAは、GeForce RTX 2080 Tiを完全に破壊するDoom EternalでのRTX 3080の新しいパフォーマンスデモンストレーションをすでに公開しており、このカードは最大の設定で4Kゲームを簡単に処理できることを明らかにしました。いくつかのAAAゲームタイトルを60 FPSで動作します。
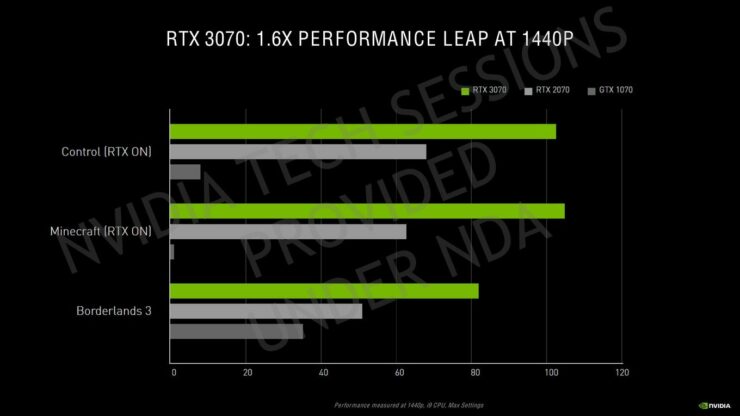
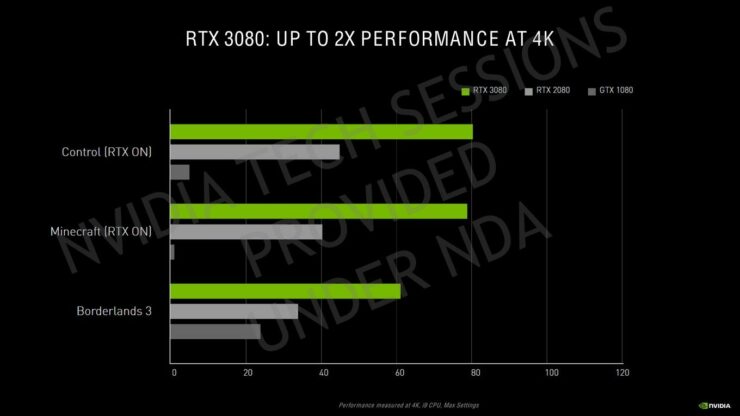
ローンチと価格については、NVIDIAは、GeForce RTX 3080が9月17日に販売開始され、9月24日にGeForce RTX 3090が続き、最後に10月にGeForce RTX 3070が販売されると発表しました。グラフィックスカードの価格は、USD$1499(RTX 3090)、USD$699(RT 3080)、およびUSD$499(RTX 3070)です。カスタムモデルは、プレミアムモデルほど価格が高くなります。
















