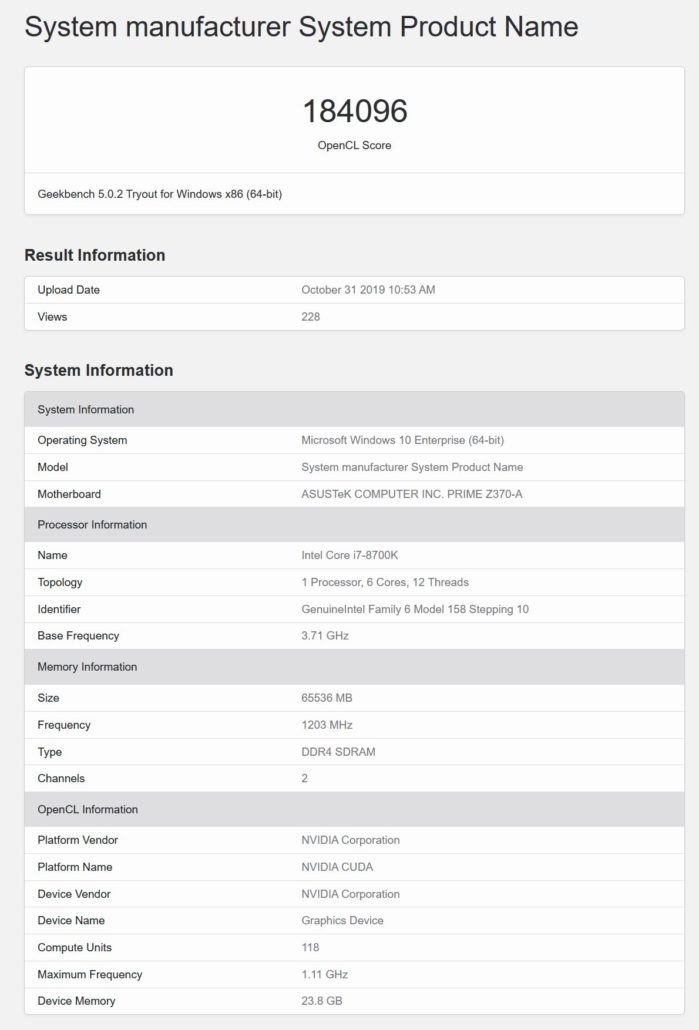
この特定のGPUは、OpenCLとCUDA Computeの両方のベンチマークでテストされました。OpenCLベンチマークでは、チップは184096ポイントを獲得しましたが、CUDAベンチマークでは169368ポイントを獲得しました。124パーツと118パーツの両方のSMパーツはCUDA 8.0上で実行されていましたが、Geekbench 5ベンチマークに対してこれらのGPUがまだ完全に最適化されていないことがわかります。コア数にわずか5%の違いがあるにもかかわらず、両方の部分のスコアに大きな違いがあります。
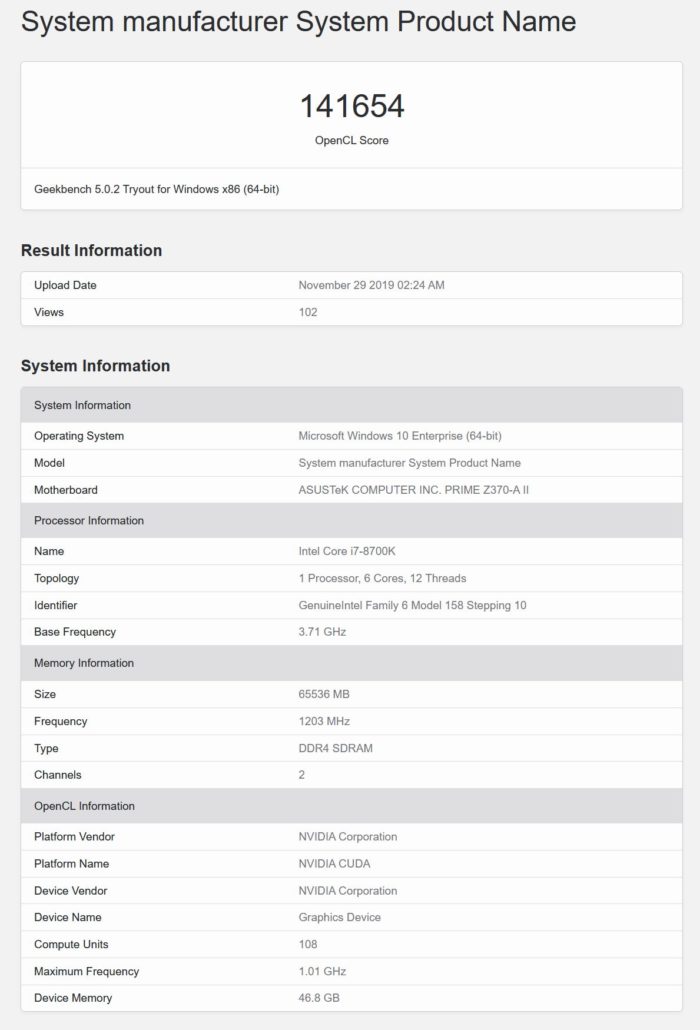
最後に、108 SMまたは6912 CUDAコアバリアントがあり、報告されているクロック速度は1.01 GHzであるか、3つのGPUの中で最も低速です。GPUにより、Tesla V100よりもCUDAコア数が35%増加し、46.8 GBのHBM2eメモリを搭載しているようです。これは、Geekbenchベンチマークが合計メモリをどのように認識するかに関するエラーである可能性があり、実際には48 GBである可能性があり、これはより理にかなっています。このGPU はGeekbench 5(CUDA)ベンチマークで141654ポイントを獲得しますが、これもまたクロック速度が遅いために最終スコアではありません。
| Tesla Graphics Card Name | NVIDIA Tesla M2090 | NVIDIA Tesla K40 | NVIDIA Telsa K80 | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA Tesla Next-Gen #1 | NVIDIA Tesla Next-Gen #2 | NVIDIA Tesla Next-Gen #3 |
|---|---|---|---|---|---|---|---|---|
| GPU Architecture | Fermi | Kepler | Maxwell | Pascal | Volta | Ampere? | Ampere? | Ampere? |
| GPU Process | 40nm | 28nm | 28nm | 16nm | 12nm | 7nm? | 7nm? | 7nm? |
| GPU Name | GF110 | GK110 | GK210 x 2 | GP100 | GV100 | GA100? | GA100? | GA100? |
| Die Size | 520mm2 | 561mm2 | 561mm2 | 610mm2 | 815mm2 | TBD | TBD | TBD |
| Transistor Count | 3.00 Billion | 7.08 Billion | 7.08 Billion | 15 Billion | 21.1 Billion | TBD | TBD | TBD |
| CUDA Cores | 512 CCs (16 CUs) | 2880 CCs (15 CUs) | 2496 CCs (13 CUs) x 2 | 3840 CCs | 5120 CCs | 6912 CCs | 7552 CCs | 7936 CCs |
| Core Clock | Up To 650 MHz | Up To 875 MHz | Up To 875 MHz | Up To 1480 MHz | Up To 1455 MHz | 1.08 GHz (Preliminary) | 1.11 GHz (Preliminary) | 1.11 GHz (Preliminary) |
| FP32 Compute | 1.33 TFLOPs | 4.29 TFLOPs | 8.74 TFLOPs | 10.6 TFLOPs | 15.0 TFLOPs | ~15 TFLOPs (Preliminary) | ~17 TFLOPs (Preliminary) | ~18 TFLOPs (Preliminary) |
| FP64 Compute | 0.66 TFLOPs | 1.43 TFLOPs | 2.91 TFLOPs | 5.30 TFLOPs | 7.50 TFLOPs | TBD | TBD | TBD |
| VRAM Size | 6 GB | 12 GB | 12 GB x 2 | 16 GB | 16 GB | 48 GB | 24 GB | 32 GB |
| VRAM Type | GDDR5 | GDDR5 | GDDR5 | HBM2 | HBM2 | HBM2e | HBM2e | HBM2e |
| VRAM Bus | 384-bit | 384-bit | 384-bit x 2 | 4096-bit | 4096-bit | 4096-bit? | 3072-bit? | 4096-bit? |
| VRAM Speed | 3.7 GHz | 6 GHz | 5 GHz | 737 MHz | 878 MHz | 1200 MHz | 1200 MHz | 1200 MHz |
| Memory Bandwidth | 177.6 GB/s | 288 GB/s | 240 GB/s | 720 GB/s | 900 GB/s | 1.2 TB/s? | 1.2 TB/s? | 1.2 TB/s? |
| Maximum TDP | 250W | 300W | 235W | 300W | 300W | TBD | TBD | TBD |
しかし興味深いのは、ローエンドGPUがより多くのメモリ容量を備えていることです。これは、NVIDIAが特定のワークロードに対してより高いメモリ容量を備えたローエンドGPUを備えているか、各GPUが異なるメモリ構成を持ち、48GB HBM2eがこの特定のGPU SKUの最高のメモリ構成。この仕様リークからわかるもう1つの最も興味深い点は、次世代のTeslaラインナップにはさまざまなGPU SKUがありますが、完全なGPUは、128 SMにパックされた8192 CUDAコアで間違いなくピークになるはずです。Volta GV100 GPUと同様に、5376 CCまたは84 SMを含むフルチップにもかかわらず、Tesla V100は5120 CUDAコア(80 SM)でピークに達したため、完全なファット(次世代)GPUは決して公開されません。では 、前のインタビューで、 NVIDIAのCEO、Jensen黄は、小さな部分は生産のためにサムスンに送信されますしながら、彼らの次の世代の7nmでのGPUの受注の大半はTSMCによって処理されることを確認していました。最後に、Jensenは次世代7nm GPUの発売時期について尋ねられましたが、彼は現時点で日付を開示するのに都合のよい時間ではないと答えました。 NVIDIAのCFOであるColette Kressとの最近のインタビューから、 7nm GPUの発表でみんなを驚かせたいと思っていることがわかっていますが、そうするための適切なタイミングを待っています。一方、AMDは、Arcturus GPUをベースとするRadeon Instinct Mi100 HPCアクセラレーターの発表も予定されています。ArcturusGPUも8192 SPを搭載しており、最新の7nm GPUアーキテクチャに基づいています。ただし、NVIDIAが過去に証明したように、より高度なノード(16nm対12nmおよび12nm対7nm)に基づく競合他社のGPUに対して超効率的かつ競争力のあるポイントまでアーキテクチャを最適化できることを証明しています。NVIDIAは、次世代GPUとまったく新しいアーキテクチャを備えたAMDと同等のプロセスであるため、実際の破壊的なパフォーマンスが確認できます。これらは間違いなくNVIDIAの次世代GPUの大きな仕様であり、3月22日に開催されるGTC 2020オンラインキーノートで、NVIDIAによる本格的な発表が期待できます。