
(Source:wccftech)
NVIDIAのRTX30シリーズは、ファンファーレと驚異的なレベルのパフォーマンスの主張と仕様で発売されましたが、すべての誇大宣伝とサードパーティのレビューの間のどこかで、約束されたパフォーマンスの倍増は跡形もなく消えました。今日は、NVIDIA GPUを悩ませている非常に興味深い現象と、すべてが見た目どおりではない理由を調査します。
NVIDIAのRTX30シリーズには2倍以上のTFLOPがありますが、すべてのパフォーマンスはどこへ?
議論は単純です。JensenはAmpereGPUの2倍のグラフィックスパワーを約束したので、ほとんどのタイトルで約2倍のシェーディングパフォーマンスが見られるはずです(DLSSやRTXのようなベルやホイッスルはありません)。これは、最も不思議なことに、起こっていません。実際、RTX 3090は、シェーディングコアの数が2倍を超えている場合でも、ゲームタイトルのシェーディングパフォーマンスがRTX 2080 Tiよりも30%から50%しか高速でないのです。結局のところ、TFLOPは、単にシェーディングクロックにクロック速度を掛けた関数です。どこかで、パフォーマンスが失われているようです。
3つのことの1つが起こっています
- Ampereの唯一のシェーディングコアはTuringよりも劣っていて、カードは実際にはそのFP32 TFLOP数を配信できません(つまり、Jensenは嘘をついています)。
- カードのBIOS /マイクロコードまたは低レベルのドライバに問題があります
- 高レベルのドライバー/ゲームエンジン/ソフトウェアスタックは、Ampereカードに存在するシェーディングコアの質量を適切に利用するためにスケールアップできません。
私たちにとって幸いなことに、これは科学的方法を使用して簡単に調査できる問題です。AmpereカードのシェーダーコアがTuringよりも何らかの形で劣っている場合、*任意の*アプリケーションを使用してFP32のパフォーマンスを2倍にすることはできないはずです。ただし、*任意の*アプリケーションで要求されたパフォーマンスを得ることができる場合は、異なります。ハードウェアの責任は免除されますが、ソフトウェアスタック/高レベルドライバーに問題があるのか、それともマイクロコードの問題なのかを確認する必要があります。非常に高いレベルの確実性でハードウェアとソフトウェアで解決することはできますが、ソフトウェア側で同じことを行うことはできません。ただし、非常に適切な推測を行うことができます。ロジックフロー図は次のとおりです。
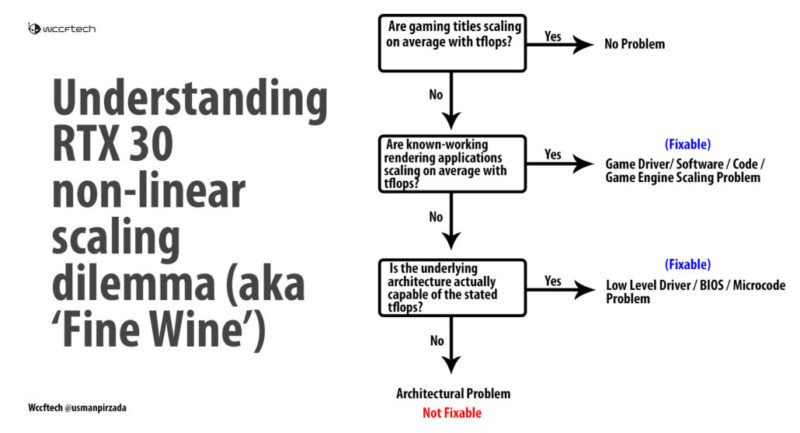
レンダリングアプリケーションは、大量のグラフィックス馬力を使用するように設計されています。言い換えれば、彼らのソフトウェアはゲームよりも指数関数的にスケーリングするようにコード化されています(実際には、ゲームが過去に16を超えるコアカウントで動作することを拒否した場合があります)。* a *レンダリングアプリケーションが、ハードウェアのせいではないよりもパフォーマンスが2倍になることを実証できる場合。コアは劣っていません。*すべての*レンダリングアプリケーションが最大限に活用できるのであれば、低レベルのドライバースタックも責任を負いません。これは、DirectX、GameReadyドライバー、およびゲームエンジンの実際のコードなどのAPIに矛先を向けます。
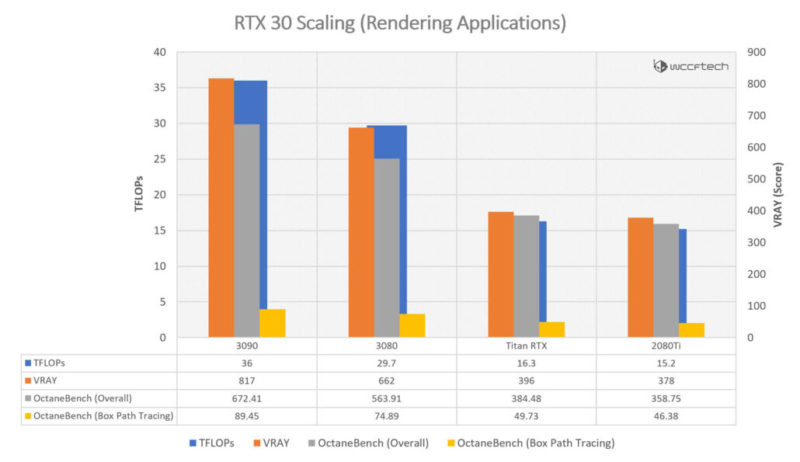 VRAYは、GPUの最もシェーディングが集中するベンチマークの1つです。これは本質的にGPU用のCinebenchです。また、プログラムがCUDAアーキテクチャ用に最適化されているため、NVIDIAカードの「ベストケース」シナリオを表します。Ampereシリーズがここで2倍のパフォーマンスを実現できない場合、他の場所では実現しません。フロー図を覚えていますか? VRAYのRTX3090は、RTX 2080Tiの2倍以上のシェーディングパフォーマンスを非常に簡単に実現します。「実世界」のワークロードで実際に2倍のパフォーマンスを出力できるプログラムがあるので、それは明らかにJensenが嘘をついておらず、RTX30シリーズが実際に主張されたパフォーマンス数値に対応していることを意味します。少なくともハードウェアに関してはです。つまり、ソフトウェア側のどこかでパフォーマンスが低下していることがわかりました。興味深いことに、OctoneはVRAYよりも少し悪いスケーリングでした。これは低レベルのドライバーが不足していることのわかる些細な証拠です。ただし、一般的に、レンダリングアプリケーションは、ゲームアプリケーションよりもはるかにスムーズにスケーリングされます。
VRAYは、GPUの最もシェーディングが集中するベンチマークの1つです。これは本質的にGPU用のCinebenchです。また、プログラムがCUDAアーキテクチャ用に最適化されているため、NVIDIAカードの「ベストケース」シナリオを表します。Ampereシリーズがここで2倍のパフォーマンスを実現できない場合、他の場所では実現しません。フロー図を覚えていますか? VRAYのRTX3090は、RTX 2080Tiの2倍以上のシェーディングパフォーマンスを非常に簡単に実現します。「実世界」のワークロードで実際に2倍のパフォーマンスを出力できるプログラムがあるので、それは明らかにJensenが嘘をついておらず、RTX30シリーズが実際に主張されたパフォーマンス数値に対応していることを意味します。少なくともハードウェアに関してはです。つまり、ソフトウェア側のどこかでパフォーマンスが低下していることがわかりました。興味深いことに、OctoneはVRAYよりも少し悪いスケーリングでした。これは低レベルのドライバーが不足していることのわかる些細な証拠です。ただし、一般的に、レンダリングアプリケーションは、ゲームアプリケーションよりもはるかにスムーズにスケーリングされます。
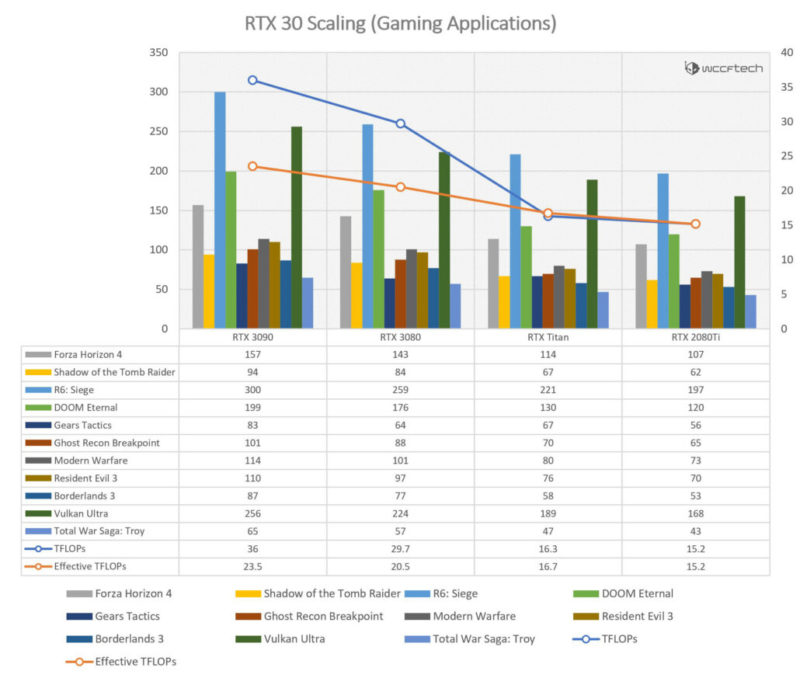
11ゲームのパネルを取りました。シェーディングパフォーマンスのみ、DLSSなし、RTXなしでゲームをテストしたかったのです。タイトルを選ぶための特別な方法論はありませんでした。RTX 3090は、RTX 2080 Tiよりも平均33%高速であることがわかりました。これは、ほとんどの場合、カードが23.5TFLOPSGPUのように機能していることを意味します。アプリケーションのレンダリングからゲームに移行するにつれて、パフォーマンスは明らかに大きな打撃を受けています。RTXシリーズが達成すべきパフォーマンス目標と実際に出力するパフォーマンス目標の間には大きな違いがあります。ただし、ここでは推測しかできません。さまざまなゲーム間で大きな変動があるため、ゲームエンジンのスケーリングには明らかな要因があり、ドライバーはRTX3090が持つ10,000以上のコアを十分に活用できないようです。
RTX 30シリーズの問題は明らかにソフトウェアベースの問題であるため(NVIDIAは文字通りGPUを非常に強力に展開しているため、現在のソフトウェアではそれを利用できません)、非常に良い問題です。AMD GPUは、常に「上質なワイン」として賞賛されてきました。NVIDIAのRTX30シリーズは、すべての高級ワインの母になると私たちは考えています。今後1年間にソフトウェアを介してこれらのカードに期待されるパフォーマンス向上のレベルは驚異的です。ゲームドライバー、API、およびゲームエンジンがスケーリングに追いつき、これらのカードに存在するシェーディングコアを処理する方法を学び、DLSSがテクノロジーとして成熟するにつれて、あなたは2倍のパフォーマンスレベルに近づきますが、最終的にはそれを超えます。
このすべてのパフォーマンスが初日に使用できないのは残念ですが、これは完全にNVIDIAのせいではない可能性があります(問題はソフトウェア側にあるだけで、ドライバーまたはゲームエンジンかどうかはわかりません。 APIはパフォーマンスの低下のせいです)そして1つ確かなことは、ソフトウェア側が成熟するにつれて、このパフォーマンスのチャンクが今後数か月でロック解除されるのを目にすることです。言い換えれば、あなたは最初のNVIDIA FineWineを見ているのです。前の世代は通常、初日に完全なパフォーマンスのロックを解除していましたが、NVIDIA RTX 30シリーズはそうではなく、購入を決定する際にはそれを覚えておくとよいでしょう。
上質なワインはさておき、これには別の非常に興味深い副作用もあります。名簿を下に移動しても、パフォーマンスのスケーリングがマイナスになることはほとんどないと思います。RTX 30シリーズのパフォーマンスは基本的にソフトウェアのボトルネックであり、ボトルネックが回転しているパラメーターはコアの数であるように見えるため、これは、パワフルでないカードではボトルネックが大幅に少なくなります。実際、私は予測を立てます。たとえば、RTX 3060 Ti(RTX 2080 Tiよりも512コア多い)は、兄よりもはるかに優れたスケーリングを体験し、RTX 2080 Tiを上回っています!コア数が少ないほど、本質的にスケーリングが向上します。
この状況はNVIDIAにとって未知の領域を表していますが、これは良い問題だと考えています。AMDのマルチコアカウントCPUの導入により、ゲームエンジンが16コア以上をサポートするように強制されたように、コアカウントを使用したNVIDIAの積極的なアプローチにより、ソフトウェア側もスケーリングに追いつく必要があります。したがって、来年には、RTX30の所有者がパフォーマンスを大幅に向上させるソフトウェアアップデートを入手することを期待しています。

















