(Source:wccftech)
NVIDIA Ampere GA100 GPUの新しい仕様のリークありました。これは、次世代GPUアーキテクチャがComputeの強力な存在になることを改めて示しています。
NVIDIA Ampere GPUは、8192 CUDAコア最大48 GBのHBM2eメモリと2 GHzを超えるコアクロックでフラッグシップGA100チップに搭載
最新の仕様は、以前にリークを投稿することを知っているユーザーが、主要なAmpere GPUであるGA100の主要な詳細をリストアップしたStage1中国語フォーラムからのものです。NVIDIAのAmpere GPUファミリーはしばらく前から知られていますが、NVIDIAがまだ一般に公開していないものです。GA100自体など、さまざまなリークで登場したAmpereファミリーのGPUがいくつかありますが、Ampereは、NVIDIAが次にHPC / Dataに導入するGPUファミリーの名前であるかどうかについて、決定的な証拠はありません。フォーラムのメンバーによると、主力のAmpere GPUはGA100であり、予想どおり、フル構成には128個のストリーミングマルチプロセッサユニットまたは8192個のCUDAコアが搭載されます。NVIDIAが使用しているプロセスノードは不明ですが、以前のレポートでは7nmとされています。新しいプロセスとGPUアーキテクチャを利用して、このチップはGPUコアで最大2.2 GHzの最大ブーストクロックを搭載すると噂され、Quadro GV100グラフィックスカードに搭載されているものより少なくとも35%速いクロック速度に飛躍しています。Quadro GV100は、1627 MHzでGV100 GPUの最速のクロックを備え、16.6 TFLOPsのFP32コンピューティングパフォーマンスを提供します。GA100 GPUのコア数とブーストクロックに基づいて、文字通り非常識なFP32コンピューティングの36 TFLOPの大規模なパフォーマンスを見ています。これはFP32コンピューティングの2倍以上の増加であり、これらの数値が合法である場合、FP64コンピューティングの馬力の異常な18 TFLOPsを見ることになります。GPUは300W TDPを搭載し、HBM2eメモリを搭載し、24 GBモデルと48 GBモデルの2種で提供されるようです。これらのメモリ構成は、32 GB HBM2eメモリを備えた他の製品も見たため、上位製品のみに対応している可能性があります。N VIDIAは、新しいAmpere GPUでTensor coresを2倍にするという噂もあります。現在の5120 CUDAコアVolta GV100 GPUは640個のTensorコアを備えているため、8192 CUDAコアを備えたAmpere GPUは、Tensor操作用に1024個のコアを備えています。
 NVIDIAの次世代GPU#1の仕様とパフォーマンス
NVIDIAの次世代GPU#1の仕様とパフォーマンス
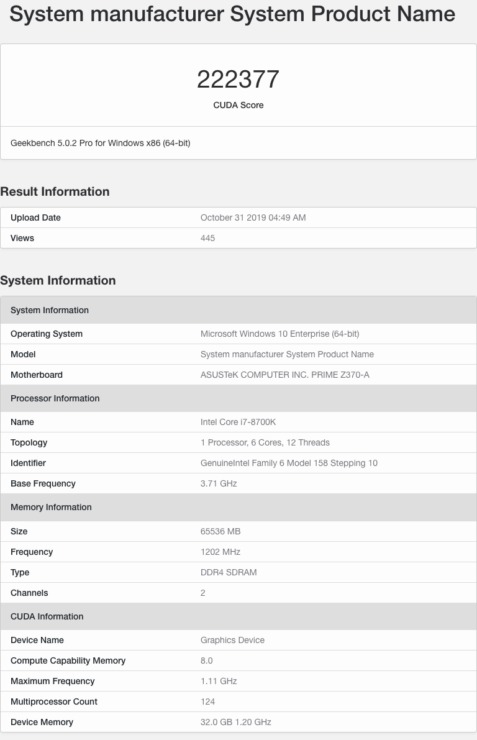
NVIDIAのプロフェッショナルGPUアーキテクチャには、ストリーミングマルチプロセッサごとに64 CUDAコアデザインが付属しているため、この最初のGPUの合計SMカウントは124で、7936 CUDAコアに相当します。これは、Tesla V100の5120コアを超えるCUDAコアの55%の増加です。GPUの最大クロック速度は1.1 GHzであり、この最終化されていないクロックで、約17.5〜18 TFLOPのFP32馬力を供給します。1200 MHzで32 GBのHBM2eメモリクロッキングを搭載し、4096ビットのバスインターフェイス上で動作します。私がHBM2eに言及する理由は、それが最新の基準であり、NVIDIAが発売時にHPCパーツで最も高度なメモリ標準を利用することが知られているためです。
コアとメモリの仕様に加えて、GPUは32 MBのL2キャッシュをパックします。これは、わずか6 MBのL2キャッシュをパックするVolta GV100 GPUの5.33倍の増加です。膨大な量のキャッシュを考えると、長年の開発が続いているNVIDIAの次世代GPUでのパフォーマンスの大幅な向上とアーキテクチャの大幅な変更が期待できます。パフォーマンスに関しては、Geekbench 5のOpenCLベンチマーク(CUDA)でGPUが222377ポイントを獲得しています。プラットフォームはCUDA 8.0を実行しており、テスト時にGPUが完全に最適化されていない可能性が高いです。
NVIDIAの次世代GPU#2仕様とパフォーマンス
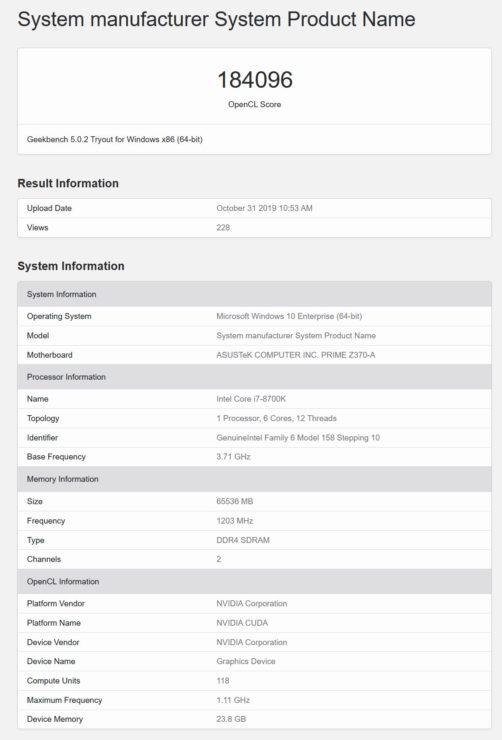
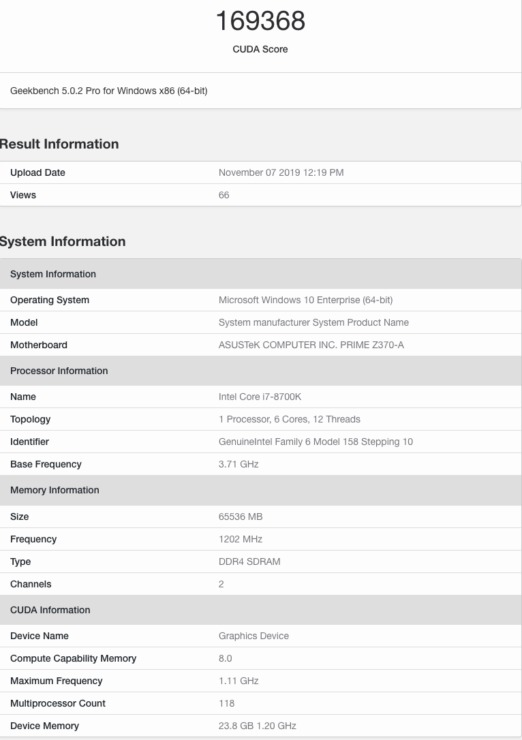
2番目のGPUは、合計118個のSMまたは7552 CUDAコアを備えています。これは、80個のSMと合計24 MBのL2キャッシュに5120個のCUDAコアが詰め込まれたTesla V100よりもCUDAコアが47.5%増加したことです。また、このGPUは1.10 GHzの最大速度でクロックされ、1200 MHzのクロック速度で3072ビットのバスに沿って実行される24 GBのHBM2eメモリを備えています。これらの速度では、このチップは合計で約16.7 TFLOPの理論上の計算馬力を提供するはずですが、再び、クロック速度は間違いなく最終的に見えず、それより高くなる可能性があります。この特定のGPUは、OpenCLとCUDA Computeの両方のベンチマークでテストされました。OpenCLベンチマークでは、チップは184096ポイントを獲得し、CUDAベンチマークでは169368ポイントを獲得しました。124と118のSMパーツは両方ともCUDA 8.0で実行されていましたが、これらのGPUはGeekbench 5ベンチマークに対してまだ完全に最適化されていないことがわかります。コアカウントがわずか5%異なるにもかかわらず、両方の部分のスコアに大きな違いがあります。
NVIDIAの次世代GPU#3仕様とパフォーマンス
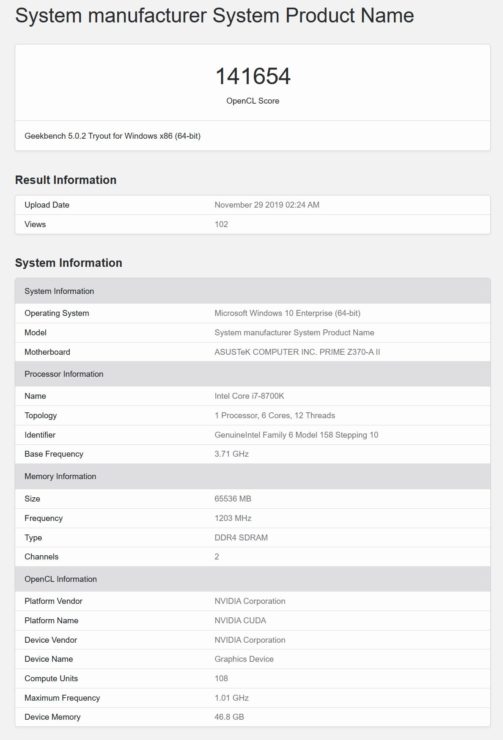
最後に、108 SMまたは6912 CUDAコアバリアントがあり、1.01 GHzのクロック速度または3つすべてのGPUの中で最も遅いことが報告されています。GPUは、Tesla V100よりもCUDAコア数が35%増加し、明らかに46.8 GBのHBM2eメモリを搭載しています。これは、Geekbenchベンチマークが合計メモリをどのように表示するかに関するエラーである可能性があり、実際には48 GBである可能性があります。このGPU はGeekbench 5(CUDA)ベンチマークで141654ポイントを獲得しますが、これもまたクロック速度が遅いため最終スコアではありません。
NVIDIA Tesla Graphics Cards Comparison
| Tesla Graphics Card Name | NVIDIA Tesla M2090 | NVIDIA Tesla K40 | NVIDIA Telsa K80 | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA Tesla Next-Gen #1 | NVIDIA Tesla Next-Gen #2 | NVIDIA Tesla Next-Gen #3 |
|---|---|---|---|---|---|---|---|---|
| GPU Architecture | Fermi | Kepler | Maxwell | Pascal | Volta | Ampere? | Ampere? | Ampere? |
| GPU Process | 40nm | 28nm | 28nm | 16nm | 12nm | 7nm? | 7nm? | 7nm? |
| GPU Name | GF110 | GK110 | GK210 x 2 | GP100 | GV100 | GA100? | GA100? | GA100? |
| Die Size | 520mm2 | 561mm2 | 561mm2 | 610mm2 | 815mm2 | TBD | TBD | TBD |
| Transistor Count | 3.00 Billion | 7.08 Billion | 7.08 Billion | 15 Billion | 21.1 Billion | TBD | TBD | TBD |
| CUDA Cores | 512 CCs (16 CUs) | 2880 CCs (15 CUs) | 2496 CCs (13 CUs) x 2 | 3840 CCs | 5120 CCs | 6912 CCs | 7552 CCs | 7936 CCs |
| Core Clock | Up To 650 MHz | Up To 875 MHz | Up To 875 MHz | Up To 1480 MHz | Up To 1455 MHz | 1.08 GHz (Preliminary) | 1.11 GHz (Preliminary) | 1.11 GHz (Preliminary) |
| FP32 Compute | 1.33 TFLOPs | 4.29 TFLOPs | 8.74 TFLOPs | 10.6 TFLOPs | 15.0 TFLOPs | ~15 TFLOPs (Preliminary) | ~17 TFLOPs (Preliminary) | ~18 TFLOPs (Preliminary) |
| FP64 Compute | 0.66 TFLOPs | 1.43 TFLOPs | 2.91 TFLOPs | 5.30 TFLOPs | 7.50 TFLOPs | TBD | TBD | TBD |
| VRAM Size | 6 GB | 12 GB | 12 GB x 2 | 16 GB | 16 GB | 48 GB | 24 GB | 32 GB |
| VRAM Type | GDDR5 | GDDR5 | GDDR5 | HBM2 | HBM2 | HBM2e | HBM2e | HBM2e |
| VRAM Bus | 384-bit | 384-bit | 384-bit x 2 | 4096-bit | 4096-bit | 4096-bit? | 3072-bit? | 4096-bit? |
| VRAM Speed | 3.7 GHz | 6 GHz | 5 GHz | 737 MHz | 878 MHz | 1200 MHz | 1200 MHz | 1200 MHz |
| Memory Bandwidth | 177.6 GB/s | 288 GB/s | 240 GB/s | 720 GB/s | 900 GB/s | 1.2 TB/s? | 1.2 TB/s? | 1.2 TB/s? |
| Maximum TDP | 250W | 300W | 235W | 300W | 300W | TBD | TBD | TBD |
昨日、AMD は、NVIDIAがPascalアーキテクチャ以来行ってきた方法と同様に、GPUを個別のゲームセグメントとコンピューティングセグメントに分割することを発表しました。新しいCDNA GPUファミリーは今年発売される予定で、NVIDIAのHPCラインナップに反して、7nmプロセスノードに基づいています。情報技術担当バイスプレジデントおよびインディアナ大学の最高情報責任者によると、今年の夏にBigRedスーパーコンピューターを導入すると、NVIDIAの次世代GPUが既存のVoltaベースのGPUに比べて75%のパフォーマンスを大幅に向上させることが明らかになりました 。GPUが過去2倍の効率で最大50%のパフォーマンス向上を実現したという過去に聞いた同様のレポートもあり、これは信じられないような偉業です。
NVIDIAは、次世代のGPUとまったく新しいアーキテクチャを備えたAMDと同等のプロセスであるため、実際の破壊的なパフォーマンスを確認できます。これらは間違いなくNVIDIAの次世代GPUの噂で報告されているいくつかの大きな仕様と数値です。