
GeForceRTX40シリーズグラフィックスカードに電力を供給するNVIDIA Ada Lovelace Gaming GPUに関する詳細が明らかになりました。新しい情報はKopte7kimiからのものであり、次世代アーキテクチャのブロック図について説明しています。
NVIDIA GeForce Ada Lovelace GPU SMブロック図詳細は、ゲーマーにとってこれまで以上に大きくて優れ魅力的
NVIDIA AdaLovelace GPUアーキテクチャはもはや謎ではありません。GeForce RTX40シリーズグラフィックスカード用の次世代AD10*シリーズSKUに電力を供給する特定の構成を学習し、ラインナップの仕様のリークも確認しました。さて、次世代グラフィックスチップ自体について純粋に話す時が来ました。
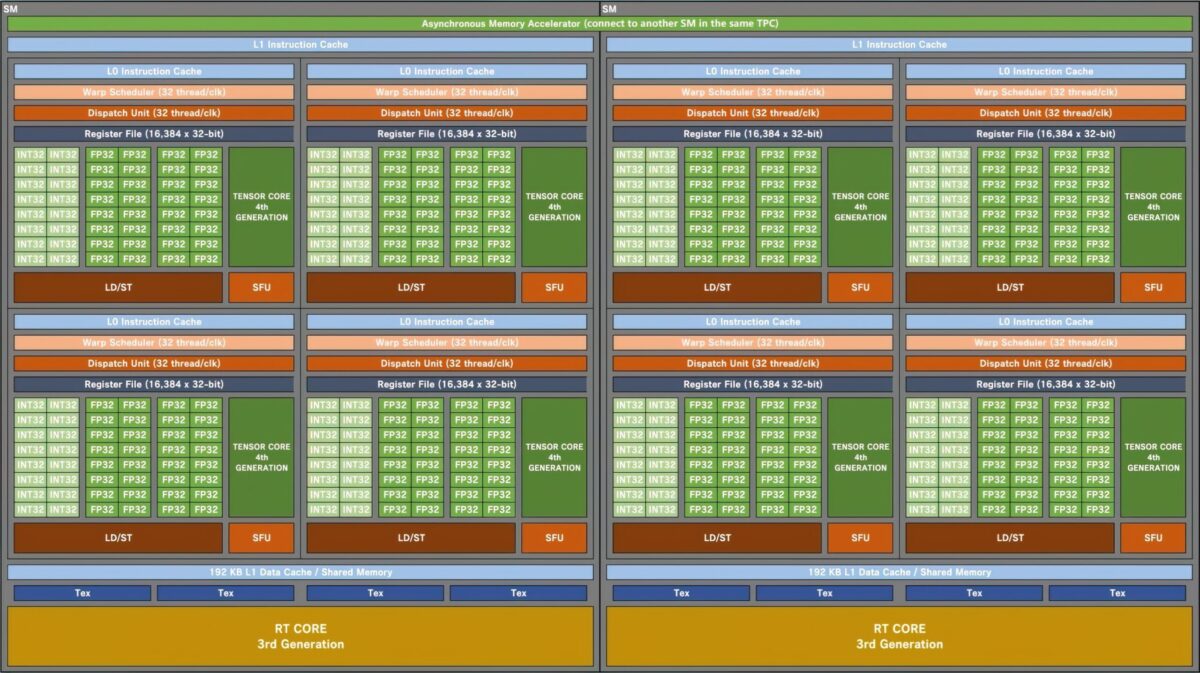
NVIDIA AD102 ‘Ada Lovelace’ Gaming GPU ‘SM’ Block Diagram (Image Credits: Kopite7kimi)

NVIDIA GA102 ‘Ampere’ Gaming GPU ‘SM’ Block Diagram
GPU構成から始めて、Kopite7kimiはトップのAD102GPUをグリーンチームの他のさまざまなGPUと比較します。これらには、ゲームに焦点を合わせたAmpereGA102とTuringTU102が含まれ、HPCに焦点を合わせたHopperGH100とAmpereGA100もリストに追加されています。HPCに焦点を当てた設計は消費者中心の製品とは大きく異なるため、AD102をその前身のゲームとのみ比較します。
NVIDIA Ada Lovelace AD102 GPUは、最大12個のGPC(グラフィックスプロセッシングクラスタ)を備えています。これは、7つのGPCのみを備えたGA102と比較して70%の増加です。各GPUは、既存のチップと同じ構成である6つのTPCと2つのSMで構成されます。各SM(ストリーミングマルチプロセッサ)は、GA102GPUと同じ4つのサブコアを収容します。変更されたのは、FP32とINT32のコア構成です。各サブコアには128個のFP32ユニットが含まれますが、FP32 + INT32ユニットの合計は192個になります。これは、FP32ユニットがIN32ユニットと同じサブコアを共有していないためです。128個のFP32コアは、64個のINT32コアとは別のものです。なので、合計で、各サブコアは128 FP32と64 INT32ユニットで構成され、合計192ユニットになります。各SMには、合計512のFP32ユニットと256のINT32ユニット、合計768のユニットがあります。また、合計24個のSMユニット(GPCごとに2個)があるため、12,288個のFP32ユニットと6,144個のINT32ユニット、合計18,432個のコアを検討しています。各SMには、SMごとに64ラップするための2つのラップスケジュール(32スレッド/ CLK)も含まれます。これは、コア(FP32 + INT32)で50%の増加であり、GA102 GPUと比較してラップ/スレッドで33%の増加です。
NVIDIA Ada Lovelace GPU Specs 'Preliminary'
| GPU Name | AD102 | GA102 | TU102 | GA100 | GH100 |
|---|---|---|---|---|---|
| GPC | 12 (Per GPU) | 1.7x | 2x | 1.5x | 1.5x |
| TPC | 6 (Per GPC) | Same | Same | 0.75x | 0.67x |
| SM | 2 (Per TPC) | Same | Same | Same | Same |
| Sub-Core | 4 (Per SM) | Same | Same | Same | Same |
| FP32 | 128 (Per SM) | Same | 2x | 2x | Same |
| FP32+INT32 | 192 (Per SM) | 1.5x | 1.5x | 1.5x | Same |
| Warps | 64 (Per SM) | 1.33x | 2x | Same | Same |
| Threads | 2048 (Per SM) | 1.33x | 2x | Same | Same |
| L1 Cache | 192 KB (Per SM) | 1.5x | 2x | Same | 0.75x |
| L2 Cache | 96 MB (Per GPU) | 16x | 16x | 2.4x | 1.6x |
| ROPs | 32 (Per GPC) | 2x | 2x | 2x | 2x |
キャッシュに移ると、これはNVIDIAが既存のAmpere GPUを大幅に強化したもう1つのセグメントです。Ada Lovelace GPUは、SMごとに192 KBのL1キャッシュをパックします。これは、Ampereよりも50%増加します。これは、最上位のAD102GPUに合計4.5MBのL1キャッシュがあります。リークに記載されているように、L2キャッシュは96MBに増加します。これは、わずか6MBのL2キャッシュをホストするAmpere GPUの16倍の増加です。キャッシュはGPU全体で共有されます。

最後に、ROPもGPCあたり32に増加し、Ampereの2倍に増加します。次世代のフラッグシップで最大384ROPを見ているのに対し、最速のAmpere GPUであるRTX3090Tiではわずか112ROPです。また、最新の第4世代Tensorおよび第3世代RT(レイトレーシング)コアがAda Lovelace GPUに注入され、DLSSおよびレイトレーシングのパフォーマンスを次のレベルに引き上げるのに役立ちます。全体として、Ada Lovelace AD102GPUは以下を提供します。
- 2x GPC(対Ampere)
- コアが50%多い(対Ampere)
- L1キャッシュが50%増加(対Ampere)
- 16倍以上のL2キャッシュ(対Ampere)
- ROPを2倍にする(対Ampere)
- 第4世代Tensorと第3世代RTコア
2〜3 GHzの範囲と言われるクロック速度は方程式に含まれないため、Ampereと比較してコアあたりのパフォーマンスを向上させる上でも主要な役割を果たします。次世代のAda LovelaceゲーミングGPUを搭載したNVIDIA GeForce RTX 40シリーズグラフィックスカードは、2022年の後半に発売される予定であり、Hopper H100 GPUと同じTSMC 4Nプロセスノードを利用すると言われています。
NVIDIA CUDA GPU (RUMORED) Preliminary
| GPU | TU102 | GA102 | AD102 |
|---|---|---|---|
| Flagship SKU | RTX 2080 Ti | RTX 3090 Ti | RTX 4090? |
| Architecture | Turing | Ampere | Ada Lovelace |
| Process | TSMC 12nm NFF | Samsung 8nm | TSMC 4N? |
| Die Size | 754mm2 | 628mm2 | ~600mm2 |
| Graphics Processing Clusters (GPC) | 6 | 7 | 12 |
| Texture Processing Clusters (TPC) | 36 | 42 | 72 |
| Streaming Multiprocessors (SM) | 72 | 84 | 144 |
| CUDA Cores | 4608 | 10752 | 18432 |
| L2 Cache | 6 MB | 6 MB | 96 MB |
| Theoretical TFLOPs | 16 TFLOPs | 40 TFLOPs | ~90 TFLOPs? |
| Memory Type | GDDR6 | GDDR6X | GDDR6X |
| Memory Capacity | 11 GB (2080 Ti) | 24 GB (3090 Ti) | 24 GB (4090?) |
| Memory Speed | 14 Gbps | 21 Gbps | 24 Gbps? |
| Memory Bandwidth | 616 GB/s | 1.008 GB/s | 1152 GB/s? |
| Memory Bus | 384-bit | 384-bit | 384-bit |
| PCIe Interface | PCIe Gen 3.0 | PCIe Gen 4.0 | PCIe Gen 4.0 |
| TGP | 250W | 350W | 600W? |
| Release | Sep. 2018 | Sept. 20 | 2H 2022 (TBC) |
(Source:wccftech)

















この記事へのコメントはありません。