
(Source:wccftech)
台湾を代表するテクノロジーパブリケーションは、今日のNVIDIAニュースに大きな影響を与えました。彼らは、同社がTSMCから次世代のHopper GPUに使用する5nm生産枠を事前予約したことを確認しました。すでに取り上げたレポートによると、AMDの7 nmでのアグレッシブなアプローチはNVIDIAを驚かせ、その問題を修正するために、Hopper GPU用にTSMCの5 nm生産枠を事前に予約しました。TSMCへの注文は確認されていますが、NIVDIAがSamsungの5nmプロセスも同様に依頼しているという噂も聞いたので、注文が分割される可能性があります。
NVIDIAは2021年にHopper GPU向けのTSMCの5nm生産枠を予約
これは大きなニュースです。現在のロードマップでは、NVIDIAが7 nmプロセスに1世代しか費やさないことを意味します(Hopperが遅延し、Ampereリフレッシュアーキテクチャが組み込まれる場合を除きます)。すでに取り上げたレポートによると、AMDはNVIDIAを7nmの動きに驚かせ、同社は将来の成長を保護するために非常に積極的になっています。TSMCの主要な5nmプロセスの部材入手を2倍にすることは、この戦略の一部とのこと。
Hopperは現在の名前に過ぎず、NVIDIAは今後、ほとんどすべてのHopperを呼び出すことを決定する可能性があることを覚えておいてください。ただし、次の次世代アーキテクチャのために5 nmの生産枠を予約している会社は確認済みで、NVIDIAは以前に少なくとも数年を単一のノードに費やしていましたが、AMDが積極的になるという状況は、会社が実際に多くの選択肢を持っていない可能性があることを意味しているようです。AMDが5nmに移行した場合、7nmプロセスに留まることはできません。これを行うと、ブランド価値が低下し、GPUテクノロジーのリーダーとしての地位を失いかねないからです。解決策は、事前に5nmの歩留まりに関する不安を払しょくするために生産枠を事前予約することでした。その為にはお金をかけることになります。競合になるAMDが現時点では、できない状況にあるためで、戦略的なものでもあります。NVIDIAがより大きなキャッシュパイルにアクセスでき、TSMCがお金を拒否しないことを考えると、GPU業界でのNVIDIAのプロセスリードの回復に大きく成功すると予想されます。
まとめ:NVIDIAのHopperGPUアーキテクチャとMCM哲学を探る
警告: NVIDIAのHopperキテクチャでのMCMの使用はすべてにおいて確認されていません。
NVIDIAのアーキテクチャは常にコンピュータのパイオニアに基づいており、これは違いがないように見えます。NvidiaのHopperアーキテクチャは、コンピューターサイエンスのパイオニアの1人であり、ハーバードマーク1の最初のプログラマーの1人であり、最初のリンカーの発明者であったグレースHopperに基づいています。彼女はまた、今日でも使用されている初期の高水準プログラミング言語であるCOBOLの開発につながった、マシンに依存しないプログラミング言語のアイデアを広めました。彼女は海軍に入隊し、第二次世界大戦中のアメリカで戦争を助けました。
ほとんどのEUVスキャナーのレチクルサイズによって制限されていることを考えると、MCMベースの設計は、おそらくGPUの進化における次のステップです。アーキテクチャの改善とMCM設計は次の論理的先駆けであり、AMDはすでにCPUの最前線で実行しているため、GPUが彼らのグランドプランの次のステップになることは必然的なことです。リークは有名なTwitterアカウントから発生し、ツイートは削除されましたが、Twitteratiがそれをキャッチして投稿しました。
AMDは、MCMベースの製品の作成に非常に優れていることをすでに証明しています。ThreadripperおよびRyzenシリーズは、HEDT市場を完全に獲得しました。彼らは、MCMパッケージを使用して、通常は6コアで非常に高価なものを16コアの手頃な価格のコンボに独力で変えました。サーバーとXeonの力がついに平均的な消費者の手に渡ったのです。しかし、なぜ同じ哲学がGPUにも機能しないのでしょうか?NVIDIAがMCMの哲学を使用してスキャナーのレチクルサイズに打ち勝ち、正味の表面積が1000mm²を超える本当に巨大なGPUを構築できることをすでに得ていると思いますが、他にも利点はあります
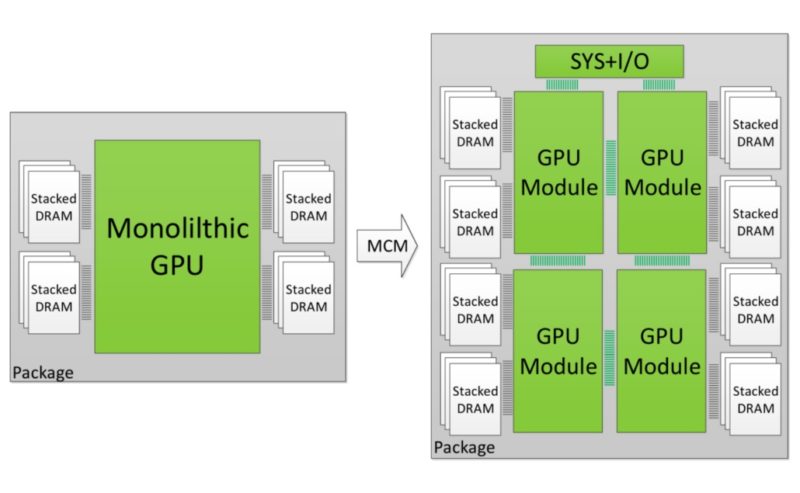
理論的には、シリアルデバイスであるCPUよりも、パラレルデバイスであるGPUの方があらゆる点でうまく機能するはずで、それだけでなく、モノリシックダイの代わりにMCMベースのアプローチにシフトするだけで、大幅な歩留まり向上が見られます。単一の巨大なダイは、収量が非常に大きく、生産コストが高く、通常は無駄が多くなります。同じダイサイズを合計した複数のチップを使用すると、すぐに収量が増加します。これは、NVIDIA Hopper GPUを支持する大きな論拠です。
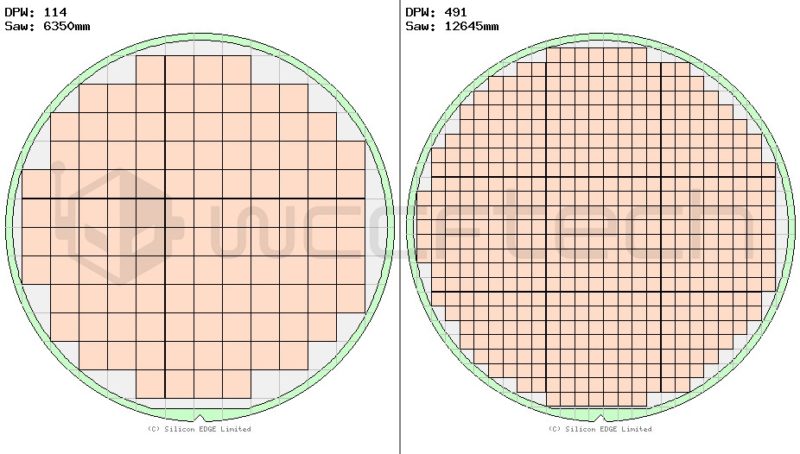
私は自由に、素敵なシリコンエッジ ツールを使用していくつかの大まかな近似を行いましたが、即座の歩留まりの向上を目にしても驚かされませんでした。22mm x 22mmのダイに相当する484mm²のダイ(例:Vega 64)を使用します。このモノリシックダイを4x 11mm x 11mmに分割すると、同じ正味表面積(484mm²)が得られ、歩留まりも向上します。概算によれば、300mmウェーハは、114個のモノリシックダイ(22×22)または491個の小さいダイ(11×11)を生成できるはずです。1つのモノリシックパーツに相当する4つの小さいダイが必要なので、122484mm²MCMダイになります。それは、7.6%の歩留まり向上です。

チップが大きいほど、歩留まりが向上します。リソグラフィ技術の上限(妥当な歩留まり)は約815mm²です。単一の300mmウェーハでは、これらのうち約64個(28.55×28.55)または285個の小さいダイ(14.27×14.27)を入手できます。これにより、合計71 MCMベースのダイが得られ、歩留まりは約11%増加します。完全な開示ですが、これは非常に大まかな概算であり、パッケージの歩留まり、長方形のダイ、その他のウェーハの形状ベースの最適化などのいくつかの要因を一切考慮していません。基本的な考え方はうまくいきます。逆に、無駄を減らしたことによるゲインの増加も考慮しません。欠陥のある815mm²のモノリシックダイは、203mm²の単一のダイよりもはるかに無駄なのです。要するに、NVIDIAはMCMベースのGPUを完全に生産する能力があり、HopperGPUでこれを実行した場合、深刻な歩留まりの利点さえ得られます。7nmノードがEUVで成熟した段階に入っていることを考えると、エッチングは非常に明確になり、このようなコンセプトを簡単にサポートできるはずですが、レチクルサイズによって制限されます。MCMベースのデザインに切り替えると、NVIDIAは815mm²を超えるネットダイサイズで巨大なGPUを構築できるようになります。したがって、それを成功に導いた非線形のパフォーマンス向上傾向を継続したい場合は、これを採用する以外に選択肢はないということです。
















