
(Source:wccftech)
AMDのRadeon Instinct Arcturus GPUは、CDNAアーキテクチャーを特徴とし、サーバー市場を狙いとするもので、Rogameによって発見されました。CDNAアーキテクチャは、次世代のRadeon Instinctグラフィックスカードに搭載され、計算に最適化されたGPU設計を活用して、データセンターに最高のパフォーマンスの計算機能を提供します。
AMDのCDNAアーキテクチャベースのArcturus GPUテストボードがリーク-次世代のRadeon Instinct、120 CU、合計7680コア
AMD Arcturus GPUは AMDの前にした2018年バックがどの7nmでGPUを導入しているすべての方法を漏洩し。Radeon VIIとNaviのラインナップは2019年にリリースされ、7nm GPUが特徴で、Naviは一般消費者市場向けです。AMDの次世代HPCおよびAI GPUは、コンシューマエンドチップとは別に設計されることが後で明らかになりました。これは、Arcturus GPUがデータセンター市場に独占的に維持されることを意味しました。AMDは最近、Radeon CDNAアーキテクチャロードマップで、すべてのCDNAベースのGPUがHPCおよびデータセンター市場向けに独占的に設計され、Radeon RDNA GPUがコンシューマーセグメントを強化することを確認しました。
仕様に関しては、以前に AMDのArcturus GPUがキャッシュを増やし、CUをVegaの2倍にすることを明らかにしました。これは、XDLOP、Rapid Packed Math、New Vector ALU&BFloat16などのデータセンター固有の機能のリストとともに、新しいCDNAアーキテクチャを備えたRadeon Instinctカードで期待されています。前のRadeon本能MI100プロト型「D34303」ボードは定格200WのTDPと32GB HBM2 VRAMは約1000から1200 MHzでクロックされるとArcturus -XLダイを装備しました。

この部分の情報はプロトタイプに基づいているため、最終的な仕様は同じではない可能性がありますが、ここに重要なポイントがあります。
- Arcturus XL GPUベース
- テストボードのTDPは200W
- 最大32 GBのHBM2メモリ
- 1000〜1200 MHzで報告されるHBM2メモリクロック
もう一度、Arcturus CDNA GPUに基づくRogameによってテストボードが発見されました。外観から、この製品は合計7680ストリームプロセッサ用の120 CUと878 MHz(750 MHz SOC)のGPUクロック速度を提供します時計)。この製品は1200 MHzでクロックされる未定義の量のHBM2メモリも備えているため、4096ビットのバスを見ると、Aquaboltが提供できる約1.2 TB / sの帯域幅が得られるはずです。しかし、NVIDIAとAMDの両方が、今年生産され、最大1.8 TB / sの帯域幅を提供できる、より高速なHBM2E ‘Flashbolt’標準を利用することになる可能性は非常に高いです。

クロック速度について言えば、テストボードの878 MHzは、過去に1334 MHzまで変化するバリエーションを見たので、かなり低速です。上記の速度では、チップは約13.5 TFLOPのFP32計算能力を誇り、Radeon Instinct MI60よりも低く、前のプロトタイプサンプルで得られた21 TFLOPも備えています。CDNA GPUの最初の反復は、最終的に25 TFLOP FP32のどこかで終了する可能性があります。
I had to forget one important detail 😅
Arcturus (Test board)
> 120CU
> 878MHz Core clock
> 750Mhz SOC clock
> 1200MHz Memory clock— _rogame (@_rogame) April 21, 2020
今年後半に発表される予定のAmpere GPUのリークに基づいて、NVIDIAは、FP32のほぼ36 TFLOPとFP64の18 TFLOPに到達すると推測されているため、次世代テスラ7nm GPUラインナップは、コンピューティングパフォーマンスの面で優位に立つ可能性があるようです。
AMD Radeon Instinct Accelerators 2020
| Accelerator Name | AMD Radeon Instinct MI6 | AMD Radeon Instinct MI8 | AMD Radeon Instinct MI25 | AMD Radeon Instinct MI60 | AMD Radeon Instinct MI60 | AMD Radeon Instinct MI100 |
|---|---|---|---|---|---|---|
| GPU Architecture | Polaris 10 | Fiji XT | Vega 10 | Vega 20 | Vega 20 | Arcturus |
| GPU Process Node | 14nm FinFET | 28nm | 14nm FinFET | 7nm FinFET | 7nm FinFET | 7nm FinFET |
| GPU Cores | 2304 | 4096 | 4096 | 3840 | 4096 | 8192? |
| GPU Clock Speed | 1237 MHz | 1000 MHz | 1500 MHz | 1746 MHz | 1800 MHz | 1334 MHz? |
| FP16 Compute | 5.7 TFLOPs | 8.2 TFLOPs | 24.6 TFLOPs | 26.8 TFLOPs | 29.6 TFLOPs | ~50 TFLOPs |
| FP32 Compute | 5.7 TFLOPs | 8.2 TFLOPs | 12.3 TFLOPs | 13.4 TFLOPs | 14.8 TFLOPs | ~25 TFLOPs |
| FP64 Compute | 384 GFLOPs | 512 GFLOPs | 768 GFLOPs | 6.7 TFLOPs | 7.4 TFLOPs | ~12.5 TFLOPs |
| VRAM | 16 GB GDDR5 | 4 GB HBM1 | 16 GB HBM2 | 16 GB HBM2 | 32 GB HBM2 | 32 GB HBM2 |
| Memory Clock | 1750 MHz | 500 MHz | 472 MHz | 500 MHz | 500 MHz | TBD |
| Memory Bus | 256-bit bus | 4096-bit bus | 2048-bit bus | 4096-bit bus | 4096-bit bus | 4096-bit bus |
| Memory Bandwidth | 224 GB/s | 512 GB/s | 484 GB/s | 1 TB/s | 1 TB/s | TBD |
| Form Factor | Single Slot, Full Length | Dual Slot, Half Length | Dual Slot, Full Length | Dual Slot, Full Length | Dual Slot, Full Length | Dual Slot, Full Length |
| Cooling | Passive Cooling | Passive Cooling | Passive Cooling | Passive Cooling | Passive Cooling | Passive Cooling? |
| TDP | 150W | 175W | 300W | 300W | 300W | 200W? |



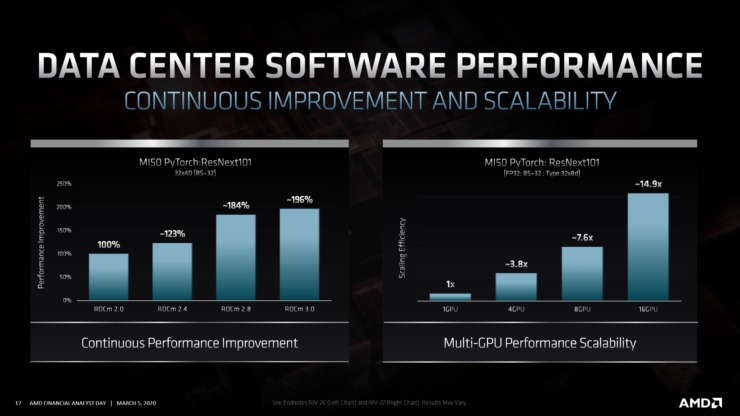

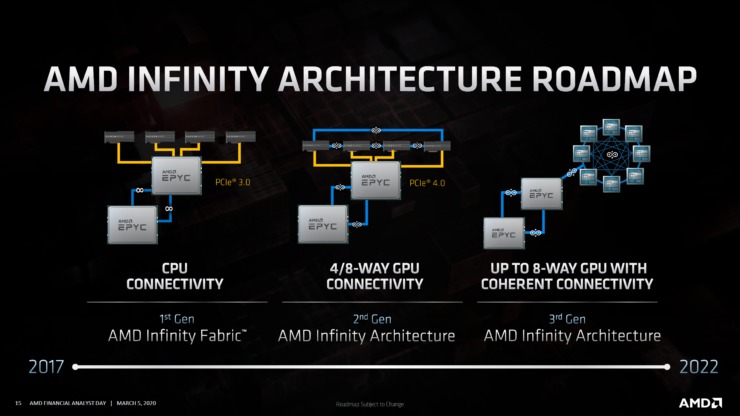

AMDはこれまで、CDNAの主な焦点は、データセンター市場におけるパフォーマンス、効率、機能、スケーラビリティであることを明らかにしました。現在、AMDのGCNアーキテクチャがこのセグメントに対応していますが、CDNAを使用して、AMDは高性能コンピューティング、機械学習、およびHPC用に特別に最適化されたGPUを作成します。第1世代のCDNA GPUは、第2世代のInfinityアーキテクチャを特徴とし、ROCm(Radeon Open Compute Platform)を利用して、主要な最適化と拡張されたスケーラビリティでデータセンターを強化します。第2世代インフィニティアーキテクチャは、単一ノードで4-8ウェイGPU接続を可能にし、新しいRadeon Instinctボードが調和して動作できるようにします。AMDは、彼らが競争力のある価格でより多くのFLOPを提供できることを証明しました。Arcturusがいつ市場に登場するかについては何も発表されていませんが、AMDは今年後半に、第1世代のCDNAアーキテクチャを特徴とするRadeon Instinct製品を示唆しています。














