
(Source:wccftech)
NVIDIAのHopper MCM GPUによる2019年の最大かつ最もエキサイティングな噂があります。このGPUは、Ampereの後継になると思われ、単一のパッケージ(ergo Multi-Chip-ModuleまたはMCM)に複数のダイを備えた非常に強力なグラフィックスカードのファミリで構成されます。
NVIDIA Hopper GPU:Ampereに続く非常に強力なMCMベースのアーキテクチャ
NVIDIAのアーキテクチャは常にコンピューターの先駆者であり、今回もこれまで同様のようです。NvidiaのHopperアーキテクチャは、コンピューターサイエンスの先駆者の1人であり、ハーバードマーク1の最初のプログラマーの1人でした。最初のリンカーの発明者だったGrace Hopperに基づいています。彼女はまた、COBOLの開発につながったマシンに依存しないプログラミング言語を広めました。これは、今日でも使用されている初期の高レベルプログラミング言語です。彼女は海軍に入隊し、第二次世界大戦中のアメリカを助けました。

MCMベースの設計は、ほぼすべてのEUVスキャナーのレチクルサイズによって制限されていることを考えると、おそらくGPU進化の次のステップです。アーキテクチャの改善とMCMデザインは次の論理的先駆者であり、AMDは既にCPUフロントで実行しているため、GPUが壮大な計画の次のステップになることは理にかなっています。リークは有名なツイッターアカウントから発生し、ツイッターはその後削除されています。
NVIDIA Hopper:GPUのマルチチップモジュールダイの哲学を探る
AMDはすでに、MCMベースの製品の作成に非常に優れていることをすでに証明しています。Threadripper と Ryzenシリーズは、HEDT市場を完全に破壊しました。彼らは、MCMパッケージを使用して、通常は6コアで非常に高価なものを、16コアで手頃な価格を可能にしたのです。サーバーとXeonのパワーをついに一般コンシューマーの手に提供しました。ここで疑問なのがなぜ同じ事がGPUでも機能しないものなのか?NVIDIAがMCM哲学を使用してスキャナーのレチクルサイズを打ち負かし、1000mm²の正味表面積を超える巨大なGPUを構築できることは既報のとおりです。
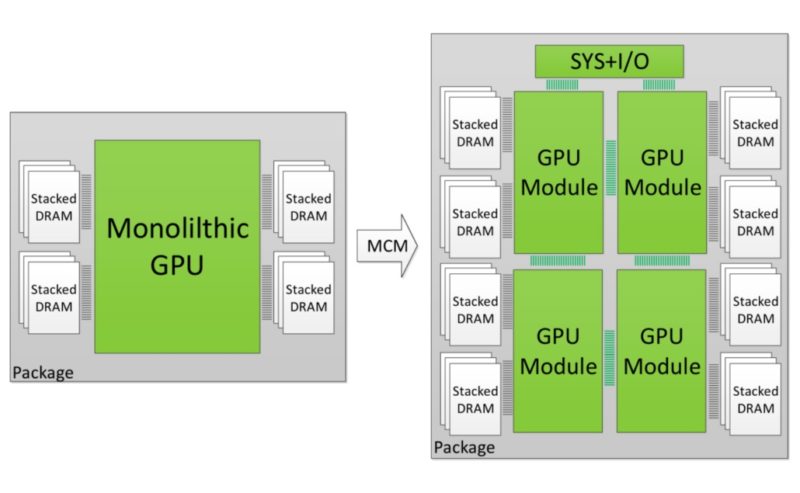
理論的には、シリアルデバイスであるCPUよりも、パラレルデバイスであるGPUの方がすべての点でうまく機能するはずなのです。。それだけでなく、モノリシックダイではなく、MCMベースのアプローチに移行することで、大幅な歩留まり向上を期待できます。単一の巨大なダイは、歩留まりが悪く、生産コストもかかり、無駄が大きくなります。合わせて同じダイサイズを複数のチップで使用すると、すぐに歩留まりが向上します。これは、NVIDIA Hopper GPUが未来を切り開く素晴らしい事なのです。
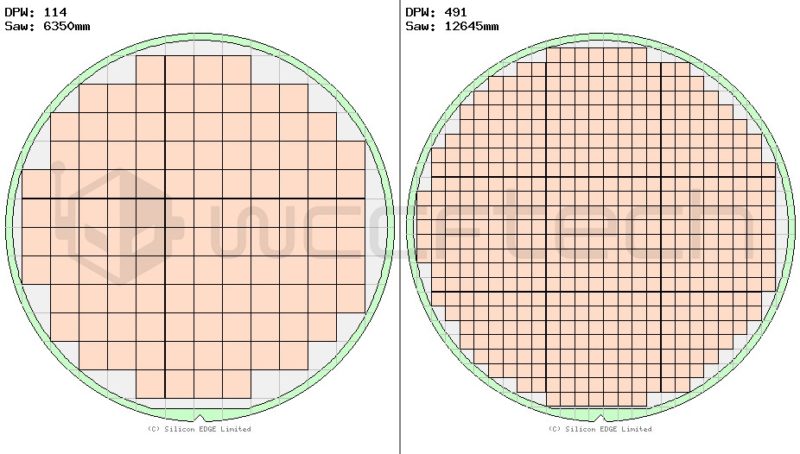
私は自由自在に、素敵なシリコンエッジ ツールを使用して大まかな近似を行いましたが、すぐに歩留まりが向上するのを見て驚きませんでした。484mm²のダイ(例:Vega 64)を取ります。これは、22mm x 22mmのダイに相当します。このモノリシックダイを4x 11mm x 11mmに分割すると、同じ正味表面積(484mm²)が得られ、歩留まりも向上します。どのくらいになるのかというと、300mmウェーハは114個のモノリシックダイ(22×22)または491個のより小さなダイ(11×11)を生成できるはずです。1つのモノリシックパーツに相当する4つの小さなダイが必要なので、122484mm²のMCMダイになります。それは、7.6%の向上になります。

歩留まりの向上は、大きなチップではさらに大きくなります。リソグラフィ技術の上限(合理的な歩留まり)は、約815mm²です。単一の300mmウェーハでは、これらのうち約64個(28.55×28.55)または285個の小さなダイ(14.27×14.27)を取得できます。これにより、合計で71個のMCMベースのダイが得られ、歩留まりが約11%向上します。これは完全な開示であり、これは非常に大雑把なものであり、パッケージの歩留まり、長方形のダイ、その他のウェーハの形状ベースの最適化などのいくつかの要因を考慮していませんが、基本的な考え方はうまくいきます 反対に、無駄を減らしてゲインを増やすことも考慮していません。故障した815mm²のモノリシックダイは、単一の203mm²のダイよりも無駄です。簡単に言えば、NVIDIAはMCMベースのGPUを完全に作成でき、Hopper GPUでこれを実行することを選択した場合、これからいくつかの深刻な歩留まりの利点が得られます。7nmノードが現在EUVで成熟段階に入っていることを考えると、エッチングは非常に明確になり、このような概念を簡単にサポートできるはずですが、レチクルのサイズによって制限されます。MCMベースの設計に切り替えると、NVIDIAは815mm²以上のネットダイサイズで巨大なGPUを構築できます。そのため、非常に成功した非線形パフォーマンスの増加傾向を継続したい場合は、これを採用する以外の選択肢はないかもしれません。















